设计一个搜索自动补全系统
在谷歌上搜索或在亚马逊购物时,当你在搜索框中输入时,会有一个或多个与搜索词相匹配的内容呈现给你。这一功能被称为自动补全、提前输入、边输入边搜索或增量搜索。图 13-1 是谷歌搜索的一个例子,当在搜索框中输"dinner"时,显示了一个自动补全的结果列表。搜索自动补全是许多产品的一个重要功能。这就把我们引向了面试问题:设计一个搜索自动补全系统,也"设计 top k"“设计 top k 最多人搜索的查询”。

理解问题并确定设计范围
处理任何系统设计面试问题的第一步是提出足够的问题来澄清需求。下面是一个应聘者与面试官互动的例子。
应聘者:是否只支持在搜索查询的开始阶段进行匹配,还是在中间也支持? 面试官:只有在搜索查询的开始阶段。 应聘者:系统应该返回多少个自动补全的建议? 面试官:5 应聘者:系统如何知道要返回哪 5 条建议? 面试官:这是由受欢迎程度决定的,由历史查询频率决定。 应聘者:系统是否支持拼写检查? 面试官:不,不支持拼写检查或自动更正。 应聘者:搜索查询是用英语吗? 面试官:是的。如果最后时间允许,我们可以讨论多语言支持。 应聘者:我们是否允许大写字母和特殊字符? 面试官:不,我们假设所有的搜索查询都是小写字母。 应聘者:有多少用户使用该产品? 面试官:1000 万 DAU。
以下是需求的摘要。
- 快速响应时间。当用户输入搜索查询时,自动补全的建议必须足够快地显示出来。一篇关于 Facebook 自动补全系统的文章[1]显示,该系统需要在 100 毫秒内返回结果。否则会造成卡顿。
- 相关性。自动补全的建议应该与搜索词相关。
- 排序。系统返回的结果必须按照流行度或其他排名模式进行排序。
- 可扩展性。系统可以处理高流量。
- 高可用性。当系统的一部分脱机、速度减慢或遇到意外的网络错误时,系统应保持可用和可访问。
粗略估计
假设有 1000 万日活跃用户(DAU)。
- 一个人平均每天进行 10 次搜索。
- 每个查询字符串有 20 个字节的数据。
- 假设我们使用 ASCII 字符编码。1 个字符 = 1 个字节
- 假设一个查询包含 4 个词,每个词平均包含 5 个字符。
- 那就是每个查询有 4 x 5 = 20 字节。
- 对于在搜索框中输入的每一个字符,客户端都会向后台发送一个自动补全建议的请求。平均来说,每个搜索查询会发送 20 个请求。例如,在你输入完"dinner"时,以下 6 个请求被发送到后端。
search?q=d
search?q=di
search?q=din
search?q=dinn
search?q=dinne
search?q=dinner
- ~24,000 次/秒(QPS)= 10,000,000 用户 * 10 次/天 * 20 个字符/24 小时/3600 秒。
- 峰值 QPS = QPS * 2 = ~48,000
- 假设每天的查询中有 20% 是新的。1000 万 * 10 次查询/天 * 每次查询 20 字节 * 20% = 0.4GB。这意味着每天有 0.4GB 的新数据被添加到存储中。
提出高层次的设计并获得认同
在高层次上,该系统被分解成两个。
- 数据收集服务。它收集用户的输入查询,并实时汇总它们。对于大型数据集来说,实时处理并不实际;但是,这是一个很好的起点。我们将在深入研究中探索一个更现实的解决方案。
- 查询服务。给定一个搜索查询或前缀,返回 5 个最常搜索的术语。
数据收集服务
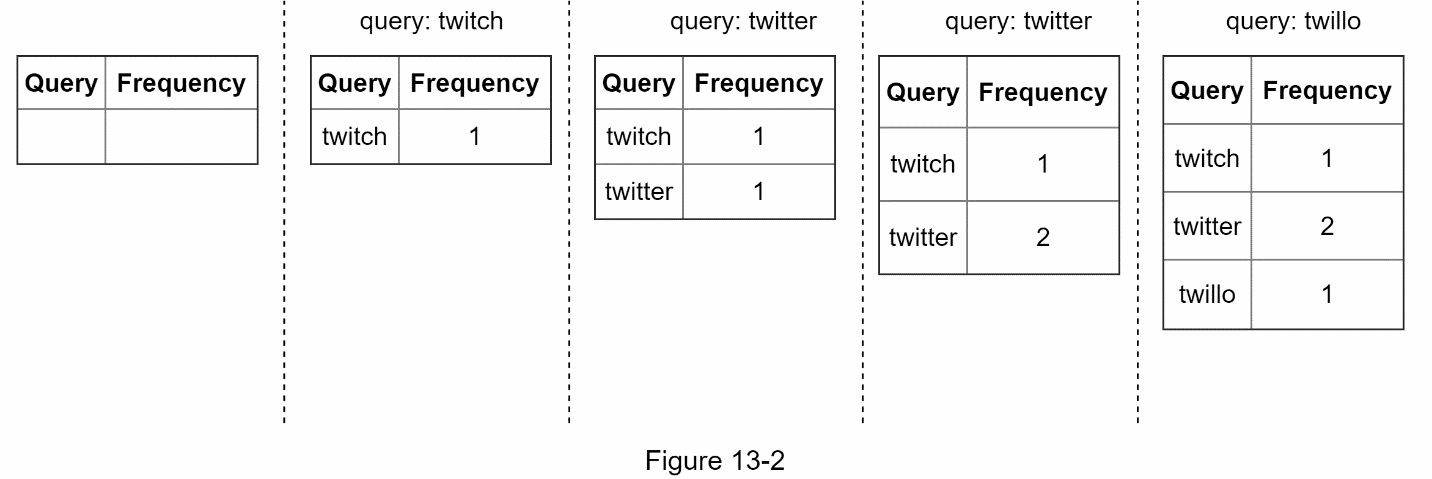
让我们用一个简化的例子来看看数据收集服务是如何工作的。假设我们有一个频率表,存储查询字符串和其频率,如图 13-2 所示。在开始时,频率表是空的。后来,用户依次输入查"twitch"、“twitter”、“twitte"“twillo”。图 13-2 显示了频率表的更新情况。
查询服务
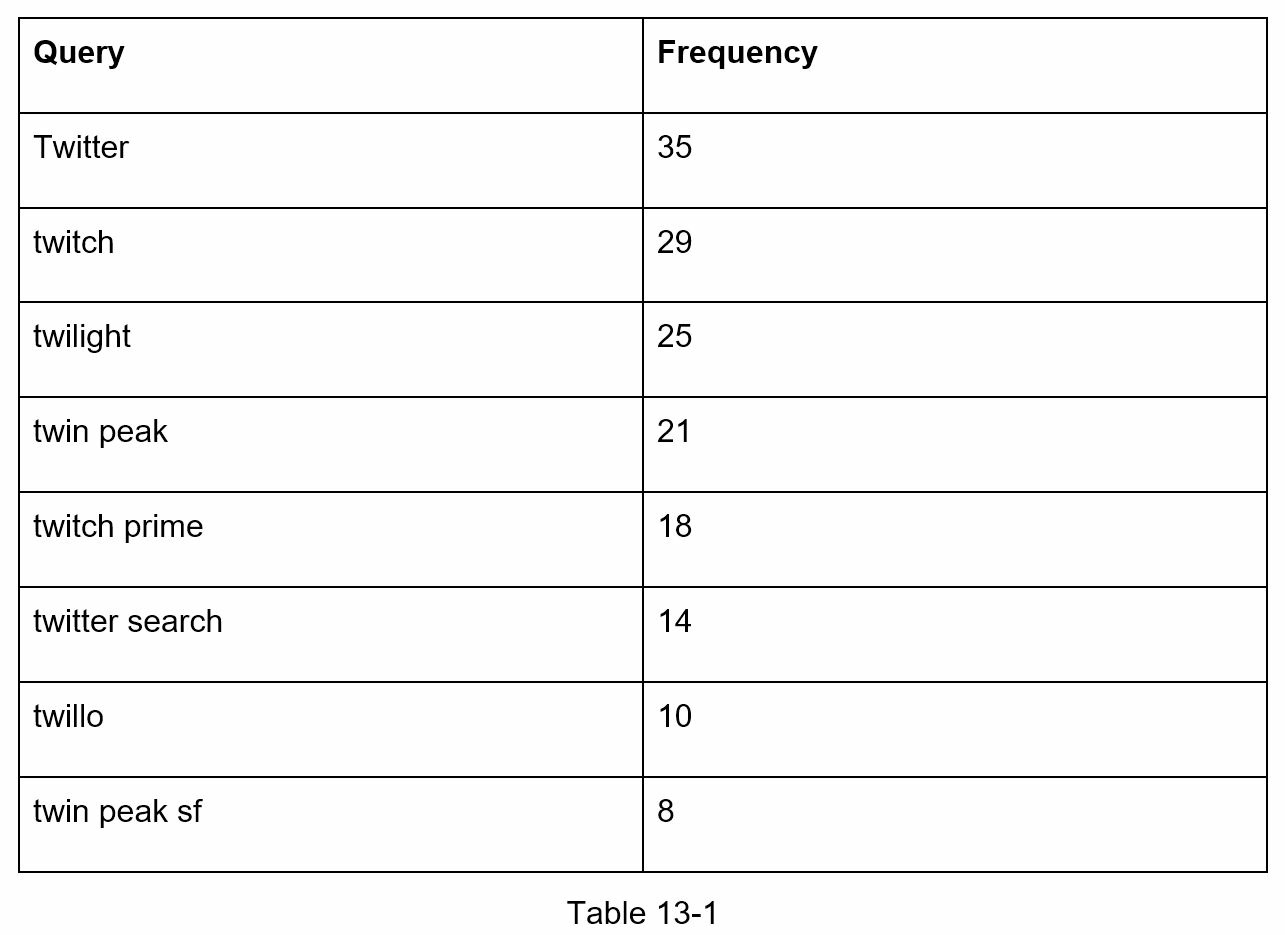
假设我们有一个频率表,如表 13-1 所示。它有两个字段。
- 查询:它存储查询字符串。
- 频率:它代表一个查询被搜索的次数。
当用户在搜索框中输"t"时,假设频率表以表 13-1 为基础,就会显示以下前 5 个被搜索的查询(图 13-3)。

要获得前 5 个经常搜索的查询,执行以下 SQL 查询。

当数据集较小时,这是一个可以接受的解决方案。当它很大时,访问数据库就会成为一个瓶颈。我们将在深入探讨优化问题。
深入设计
在高层设计中,我们讨论了数据收集服务和查询服务。高层设计并不是最优的,但它可以作为一个很好的起点。在本节中,我们将深入研究几个组件,并探讨以下的优化方法。
- Trie 数据结构
- 数据收集服务
- 查询服务
- 扩展存储
- Trie 操作
Trie 数据结构
在高层设计中,关系型数据库被用于存储。然而,从关系型数据库中获取前 5 个搜索查询的效率很低。数据结构 trie(前缀树)被用来克服这个问题。由于 trie 数据结构对系统至关重要,我们将投入大量时间来设计一个定制的 trie。请注意,一些想法来自文章[2]和[3]。
了解基本的 trie 数据结构对于这个面试问题是至关重要的。然而,这更像是一个数据结构问题,而不是一个系统设计问题。此外,许多在线材料都解释了这个概念。在本章中,我们将只讨论 trie 数据结构的概述,并着重讨论如何优化基本 trie 以提高响应时间。
Trie(发音"try”)是一种树状的数据结构,可以紧凑地存储字符串。这个名字来自于检索一词,表明它是为字符串检索操作设计的。trie 的主要思想包括以下内容。
- trie 是一个树状的数据结构。
- 根代表一个空字符串。
- 每个节点存储一个字符,有 26 个子节点,每个子节点代表一个可能的字符。为了节省空间,我们不画空链接。
- 每个树节点代表一个单词或一个前缀字符串。
图 13-5 显示了一个带有搜索查"tree"、“try”、“true”、“toy”、“wish”、“wi"的 trie。搜索查询以较粗的边框突出显示。

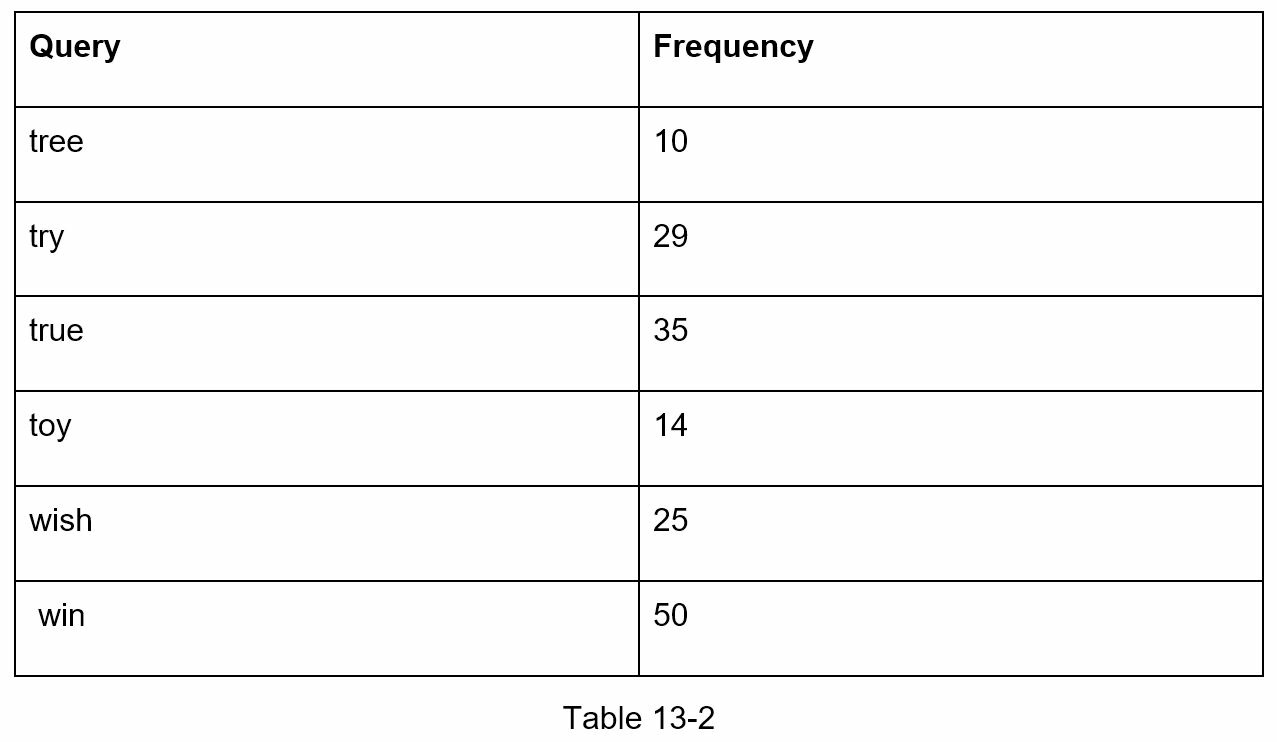
基本的 trie 数据结构在节点中存储字符。为了支持按频率排序,需要将频率信息包含在节点中。假设我们有以下频率表。
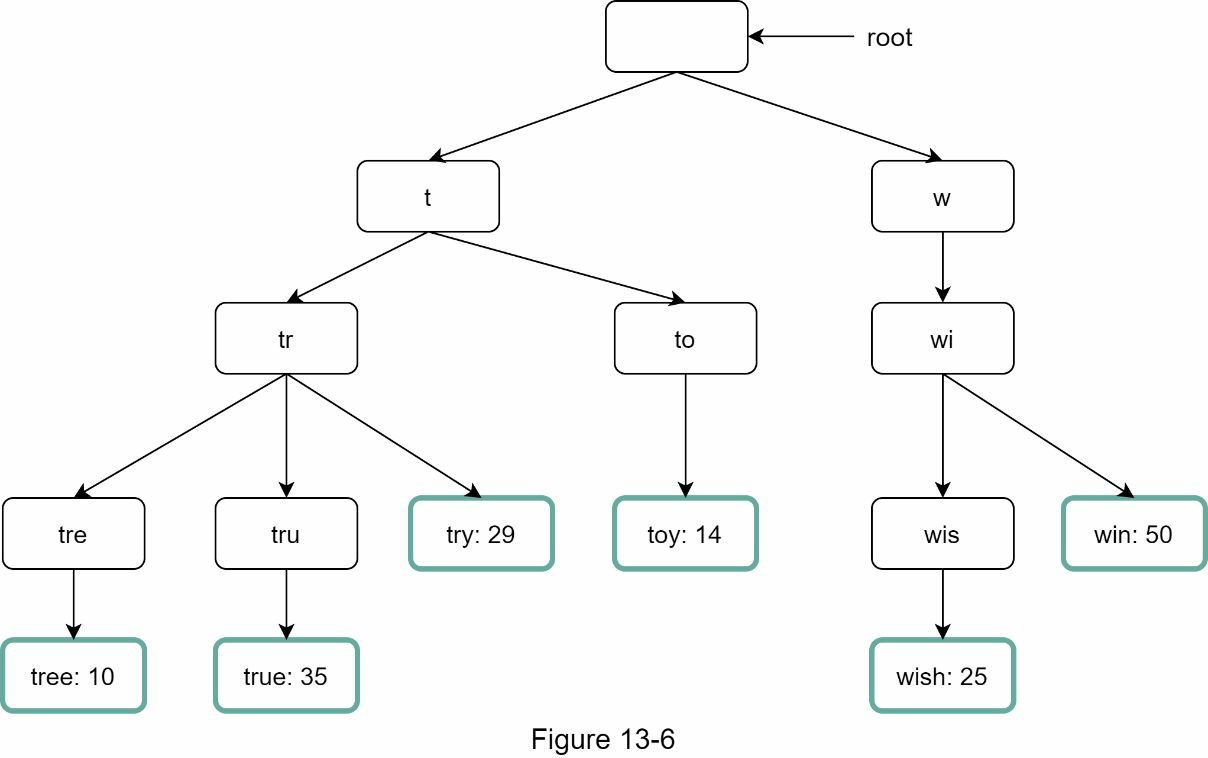
在向节点添加频率信息后,更新的三角形数据结构如图 13-6 所示。
自动补全是如何在 Trie 中工作的?在深入研究算法之前,让我们定义一些术语。
- p:前缀的长度
- n:trie 中的节点总数
- c:一个给定节点的子节点的数量
获得前 k 个搜索次数最多的查询的步骤如下。
- 找到前缀。时间复杂度。O(p)。
- 从前缀节点遍历子树,得到所有有效的子节点。如果一个子节点能够形成一个有效的查询字符串,它就是有效的。时间复杂度。O(c)
- 对子节点进行排序,得到前 k 名。O(clogc)
让我们用一个如图 13-7 所示的例子来解释这个算法。假设 k 等于 2,一个用户在搜索框中输"tr”。该算法的工作原理如下。
- 第 1 步:找到前缀节"tr"。
- 第 2 步:遍历子树,得到所有有效的子节点。在这种情况下,节点[tree: 10]、[true: 35]、[try: 29]是有效的。
- 第 3 步:对子节点进行排序,得到前两名。[true: 35]和[try: 29]是前缀"t"的前两个查询。

这个算法的时间复杂度是上述每个步骤所花费的时间之和。O(p) + O(c) + O(clogc)
上述算法是直截了当的。然而,它太慢了,因为在最坏的情况下,我们需要遍历整个 trie 来获得前 k 个结果。下面是两个优化方案。
- 限制前缀的最大长度
- 缓存每个节点上的顶级搜索查询 让我们逐一看看这些优化措施。
限制前缀的最大长度 用户很少在搜索框中输入一个长的搜索查询。因此,可以说 p 是一个小的整数,比如 50。如果我们限制前缀的长度,“查找前"的时间复杂度就可以从 O(p)减少到 O(小常数),也就是 O(1)。
在每个节点上缓存顶级搜索查询 为了避免遍历整个三角形,我们在每个节点上存储前 k 个最常用的查询。由于 5 到 10 个自动补全的建议对用户来说已经足够了,所以 k 是一个相对较小的数字。在我们的具体案例中,只有前 5 个搜索查询被缓存。
通过在每个节点缓存顶级搜索查询,我们大大降低了检索前 5 个查询的时间复杂性。然而,这种设计需要大量的空间来存储每个节点的顶级查询。用空间换取时间是非常值得的,因为快速响应时间非常重要。
图 13-8 显示了更新后的 trie 数据结构。前 5 个查询被存储在每个节点上。例如,前缀"b"的节点存储以下内容。[best: 35, bet: 29, bee: 20, be: 15, beer: 10]。

让我们重新审视一下应用这两个优化后的算法的时间复杂性。
- 寻找前缀节点。时间复杂度。O(1)
- 返回 top k。由于 top k 查询被缓存,这一步的时间复杂度为 O(1)。由于每个步骤的时间复杂度都降低到 O(1),我们的算法只需要 O(1)来获取 top k 查询。
数据收集服务
在我们之前的设计中,每当用户键入一个搜索查询,数据就会实时更新。由于以下两个原因,这种方法并不实用。
- 用户每天可能会输入数十亿次的查询。在每次查询中更新 trie 会大大减慢查询服务的速度。
- 一旦建立了 trie,顶级建议可能不会有太大变化。因此,没有必要经常更新 trie。
为了设计一个可扩展的数据收集服务,我们研究了数据的来源和数据的使用方式。像 Twitter 这样的实时应用需要最新的自动补全建议。然而,许多谷歌关键词的自动补全建议可能每天都不会有太大变化。
尽管用例不同,数据收集服务的底层基础仍然是相同的,因为用于建立三角形的数据通常来自分析或日志服务。
图 13-9 显示了重新设计的数据收集服务。每个组件都被逐一检查。
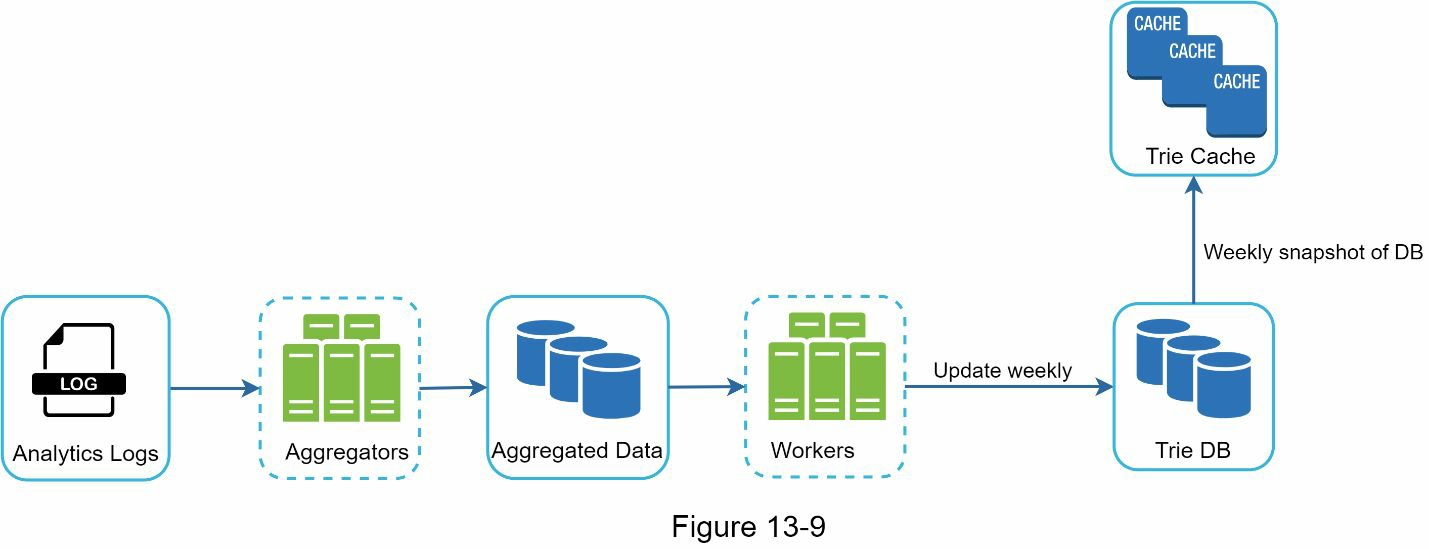
分析日志。它存储关于搜索查询的原始数据。日志是只附加的,不被索引。表 13-3 显示了一个日志文件的例子。

聚合器。
分析日志的大小通常非常大,而且数据的格式也不对。我们需要聚合数据,以便我们的系统可以轻松处理这些数据。
根据不同的用例,我们可能会以不同的方式聚合数据。对于 Twitter 这样的实时应用,我们会在较短的时间间隔内聚合数据,因为实时结果很重要。另一方面,对于许多用例来说,聚集数据的频率较低,比如每周一次,可能就足够了。在采访过程中,验证实时结果是否重要。我们假设 Trie 每周都会重建。
聚合的数据。
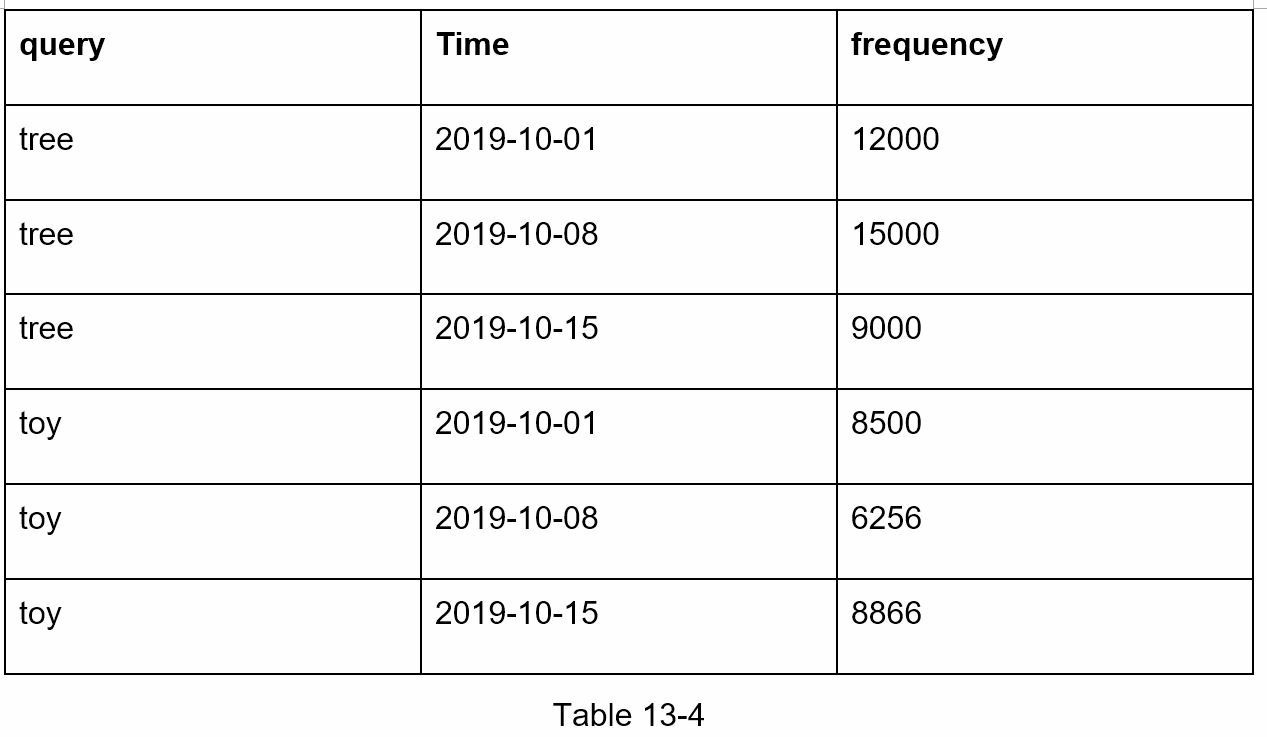
表 13-4 显示了一个每周汇总数据的例子。“时"字段代表一个星期的开始时间。“频"字段是该周相应查询的出现次数之和。
工作者。工作者是一组服务器,以固定的时间间隔执行异步工作。他们建立 Trie 数据结构并将其存储在 Trie DB 中。
Trie Cache。Trie Cache 是一个分布式缓存系统,它将 Trie 保存在内存中,以便快速读取。它每周对数据库进行一次快照。
Trie DB。Trie DB 是持久性存储。有两个选项可用于存储数据。
- 文件存储。由于每周都会建立一个新的 Trie,我们可以定期对其进行快照,将其序列化,并将序列化的数据存储在数据库中。像 MongoDB[4]这样的文档存储很适合序列化的数据。
- 键值存储。通过应用以下逻辑,一个 trie 可以用哈希表的形式来表示 [4]。
- trie 中的每个前缀都被映射到哈希表中的一个键。
- 每个 trie 节点上的数据被映射到哈希表中的一个值。
图 13-10 显示了 trie 和哈希表之间的映射关系。

在图 13-10 中,左边的每个 trie 节点被映射到右边的 <key, value> 对。如果你不清楚键值存储如何工作,请参考第 6 章:设计键值存储。
查询服务
在高层设计中,查询服务直接调用数据库来获取前 5 个结果。图 13-11 显示了改进后的设计,因为之前的设计效率很低。
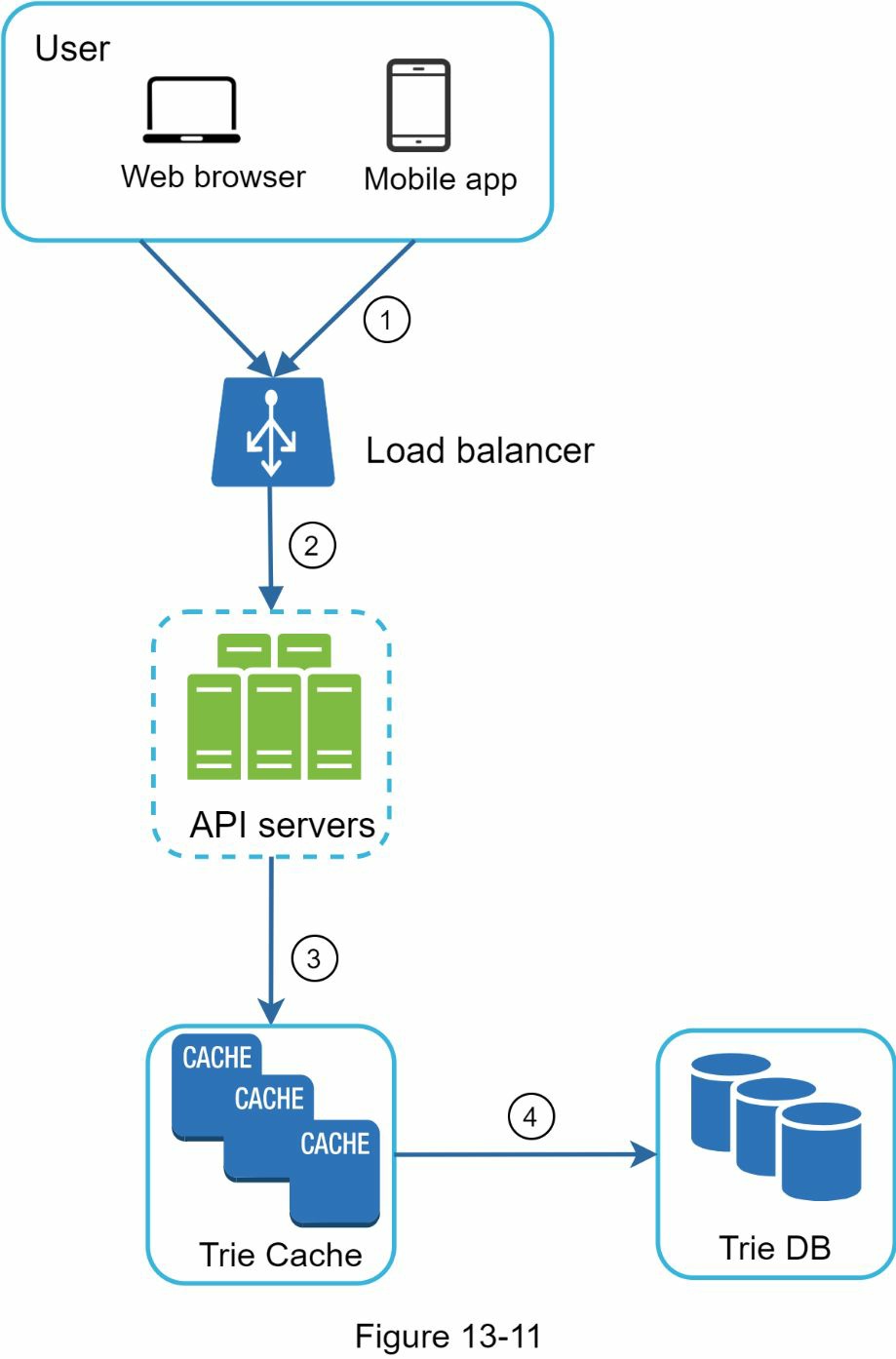
- 一个搜索查询被发送到负载均衡器。
- 负载平衡器将请求路由到 API 服务器。
- API 服务器从 Trie Cache 获得 Trie 数据,并为客户构建自动补全的建议。
- 如果数据不在 Trie Cache 中,我们将数据补充回缓存中。这样一来,所有对同一前缀的后续请求都会从缓存中返回。缓存缺失可能发生在缓存服务器没有内存或离线的情况下。
查询服务需要快如闪电的速度。我们提出以下优化方案。
- AJAX 请求。对于网络应用,浏览器通常会发送 AJAX 请求来获取自动补全的结果。AJAX 的主要好处是,发送/接收请求/响应时不会刷新整个网页。
- 浏览器缓存。对于许多应用程序,自动补全搜索建议可能不会在短时间内
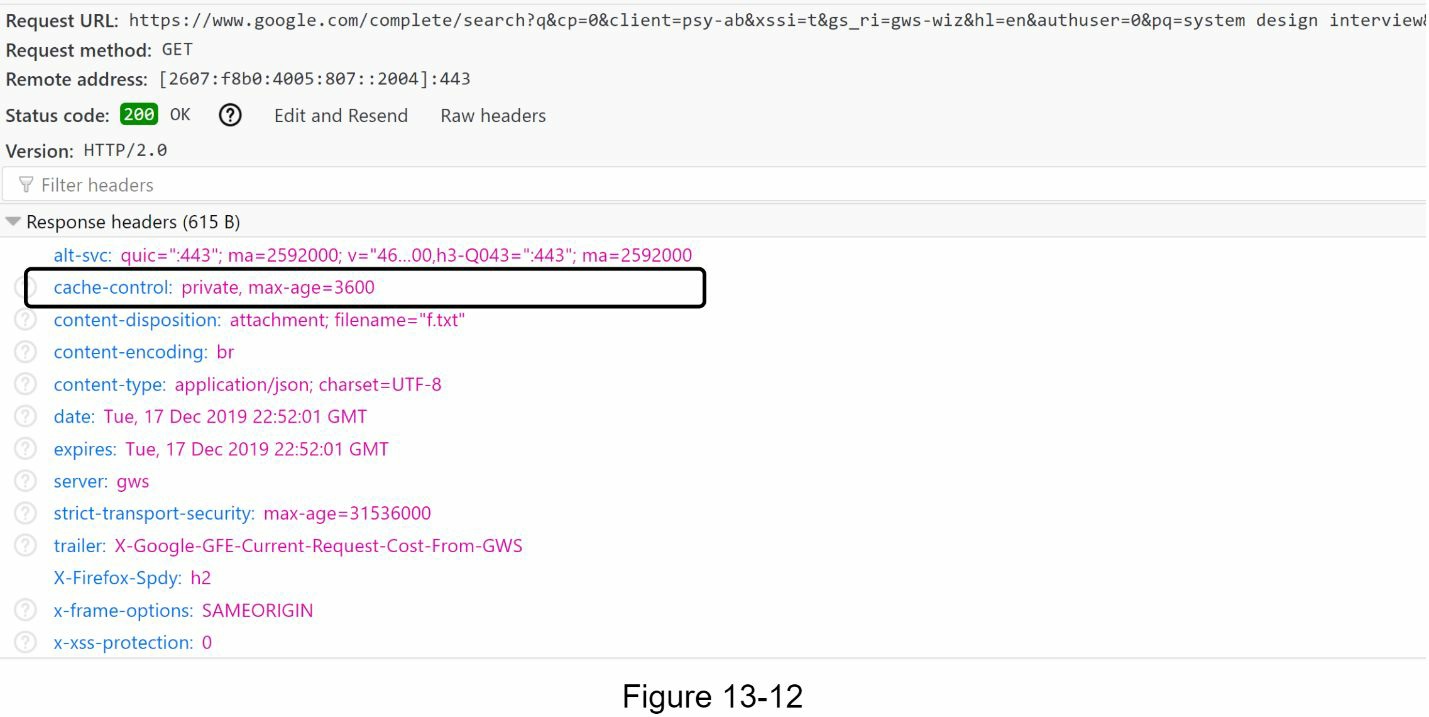
- 短时间内变化不大。因此,自动补全的建议可以保存在浏览器缓存中,以允许后续请求直接从缓存中获得结果。谷歌搜索引擎也使用同样的缓存机制。图 13-12 显示了当你在 Google 搜索引擎上输"系统设计面"时的响应头。正如你所看到的,Google 将结果在浏览器中缓存了 1 小时。请注意:cache-control 中"privat"意味着结果是为单个用户准备的,不能被共享缓存所缓存。“maxage=360"意味着缓存的有效期为 3600 秒,也就是一个小时。
- 数据采样。对于一个大规模的系统,记录每个搜索查询需要大量的处理能力和存储。数据采样很重要。例如,每 N 个请求中只有 1 个被系统记录下来。
Trie 操作
Trie 是自动补全系统的一个核心组成部分。让我们来看看 Trie 操作(创建、更新和删除)是如何工作的。
创建
Trie 是由工人使用聚合的数据创建的。数据的来源是来自分析日志/数据库。
更新
有两种方法来更新 trie。
选项 1:每周更新 trie。一旦一个新的 trie 被创建,新的 trie 将取代旧的 trie。
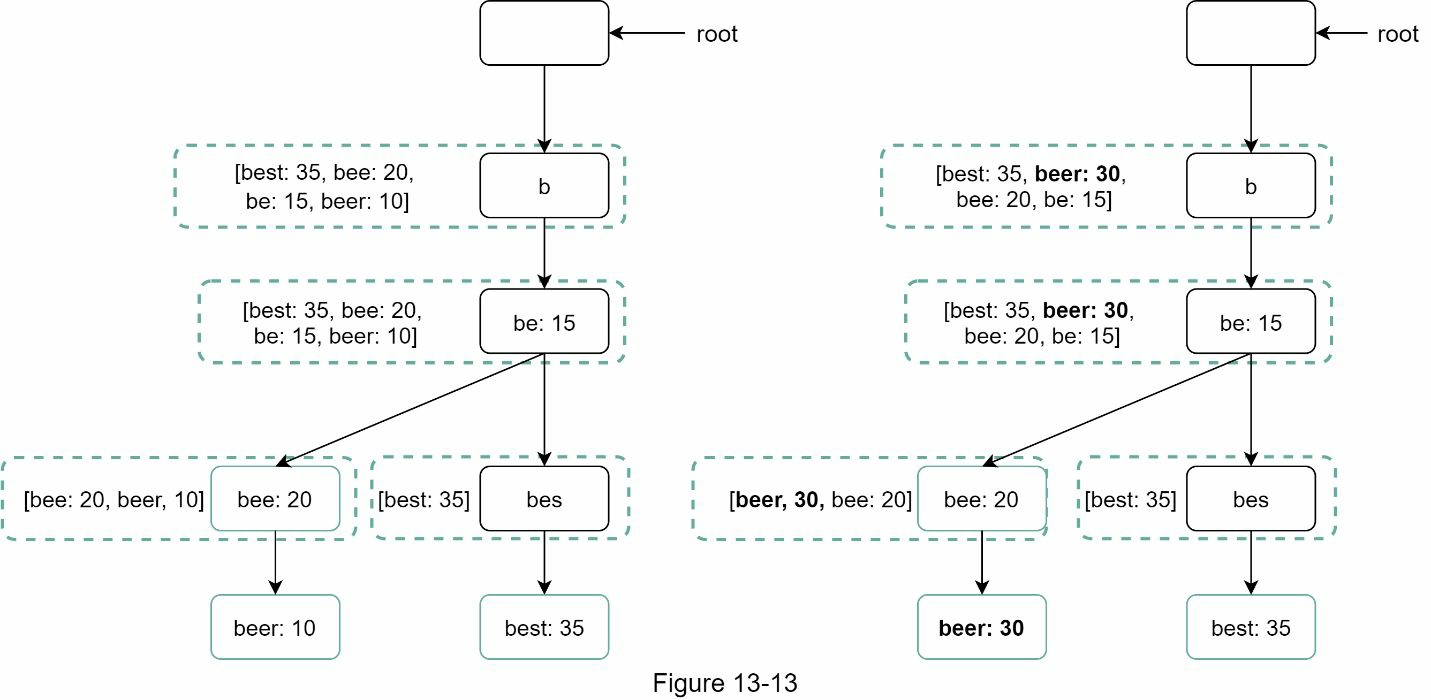
选项 2:直接更新单个 trie 节点。我们尽量避免这种操作,因为它很慢。然而,如果 trie 的大小较小,它是一个可以接受的解决方案。当我们更新一个 trie 节点时,它的祖先一直到根都必须被更新,因为祖先存储了子节点的顶级查询。图 13-13 显示了一个更新操作的例子。在左边,搜索查"啤"的原始值是 10。在右边,它被更新为 30。正如你所看到的,该节点和它的祖先"啤"值被更新为 30。
删除
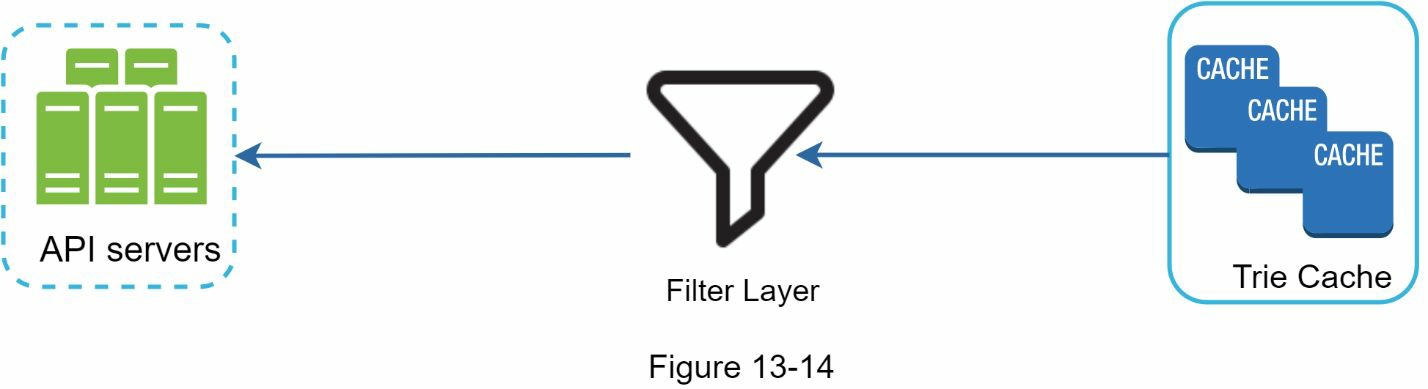
我们必须删除仇恨的、暴力的、色情的、或危险的自动补全建议。我们在 Trie Cache 前面添加一个过滤层(图 13-14)来过滤掉不需要的建议。有了过滤层,我们就可以根据不同的过滤规则灵活地删除结果。不需要的建议被异步地从数据库中移除,这样正确的数据集将在下一个更新周期中被用于构建 Trie。
扩展存储
现在我们已经开发了一个将自动补全查询带给用户的系统,是时候解决当 trie 增长到无法在一台服务器中容纳时的可扩展性问题了。
由于英语是唯一被支持的语言,一种天真的分片方式是基于第一个字符。下面是一些例子。
- 如果我们需要两台服务器来存储,我们可以在第一台服务器上存储从’a’到’m’的查询,而在第二台服务器上存储’n’到’z’的查询。
- 如果我们需要三台服务器,我们可以把查询分成’a’到’i’,‘j’到’r’,’s’到’z’。
按照这个逻辑,我们可以将查询分成 26 个服务器,因为英语中有 26 个字母。让我们把基于第一个字符的分片定义为第一层分片。要存储超过 26 个服务器的数据,我们可以在第二层甚至第三层进行分片。例如,以’a’开头的数据查询可以分成 4 个服务器:‘aa-ag’、‘ahan’、‘ao-au’和’av-az’。
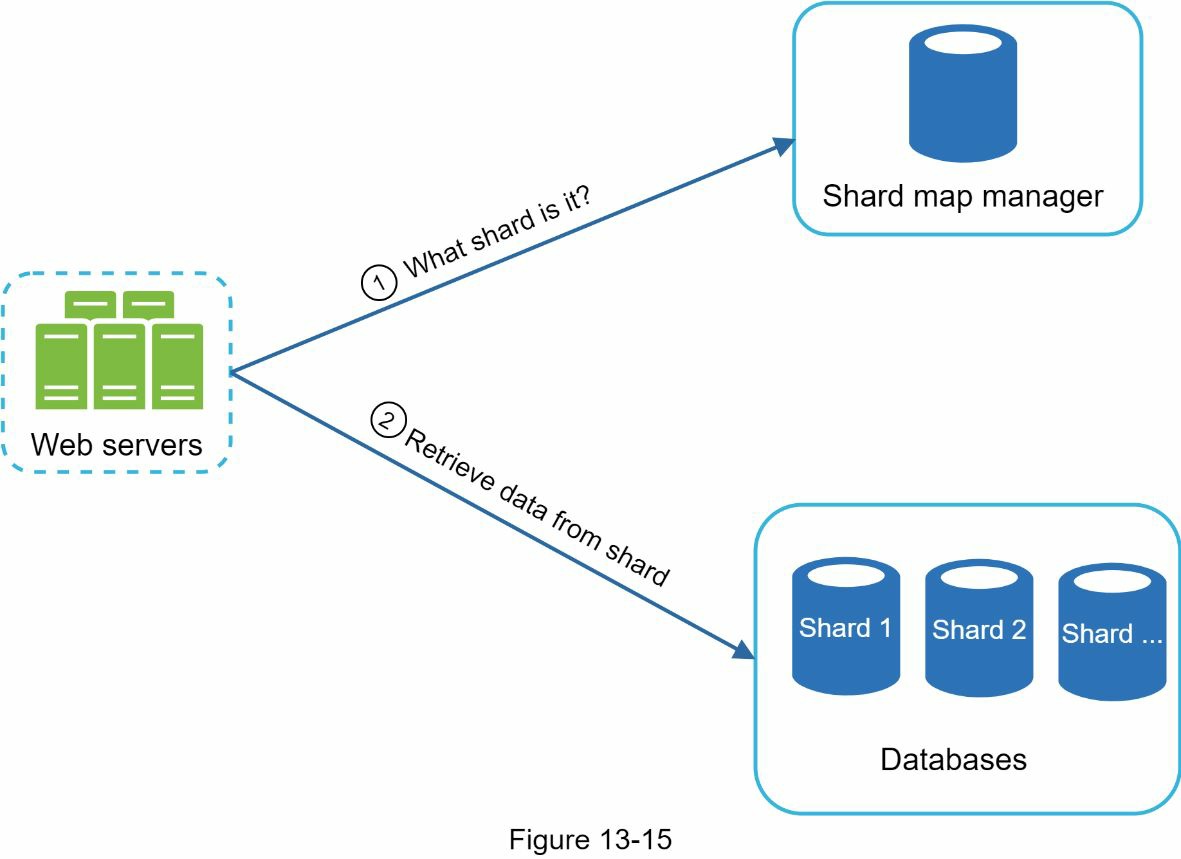
乍一看,这种方法似乎很合理,直到你意识到,以字母’c’开头的单词比’x’多得多。这就造成了分布不均。为了缓解数据不平衡问题,我们分析了历史数据分布模式,并应用了更智能的分片逻辑,如图 13-15 所示。分片地图管理器维护着一个查找数据库,用于识别行应该被存储在哪里。例如,如果"u”、“v”、“w”、“x"的历史查询数量相似,我们可以维护两个分片:一个用"s”,另一个用”““z”。
总结
在你完成深层研究后,你的面试官可能会问你一些后续问题。
面试官:你如何扩展你的设计以支持多语言?
为了支持其他非英语的查询,我们在 trie 节点中存储 Unicode 字符。如果你对 Unicode 不熟悉,这里有一个定义。“一个编码标准涵盖了世界上所有书写系统的所有字符,包括现代和古代的”[5]。
面试官。如果一个国家的顶级搜索查询与其他国家不同怎么办?
在这种情况下,我们可能会为不同国家建立不同的尝试。为了提高响应时间,我们可以将尝试存储在 CDN 中。
面试官。我们如何支持趋势性(实时)的搜索查询?
假设一个新闻事件爆发了,一个搜索查询突然变得很流行。我们原来的设计将无法工作,因为。
- 离线工人还没有被安排更新 Trie,因为这被安排在每周的基础上运行。
- 即使它被安排了,也需要太长的时间来建立三角形。
构建实时搜索自动补全系统很复杂,超出了本书的范围,所以我们只给出一些想法。
- 通过分片减少工作数据集。
- 改变排名模型,给最近的搜索查询分配更多的权重。
- 数据可能以流的形式出现,所以我们不能一次就获得所有的数据。流式数据意味着数据是连续产生的。流处理需要一套不同的系统。Apache Hadoop MapReduce [6], Apache Spark Streaming [7], Apache Storm[8]、Apache Kafka [9]等。因为所有这些主题都需要特定的领域知识,所以我们在此不做详述。
恭喜你走到这一步! 现在给自己拍拍背吧。干得好!
参考资料
[1] The Life of a Typeahead Query
[2] How We Built Prefixy: A Scalable Prefix Search Service for Powering Autocomplete
[3] Prefix Hash Tree An Indexing Data Structure over Distributed Hash Tables
[4] MongoDB wikipedia
[5] Unicode frequently asked questions
[6] Apache hadoop
[7] Spark streaming
[8] Apache storm
[9] Apache kafka