设计一个新闻源系统
在本章中,你被要求设计一个新闻源系统。什么是新闻源?根据 Facebook 的帮助页面,“新闻源是在你的主页中间不断更新的故事列表。新闻提要包括状态更新、照片、视频、链接、应用活动,以及你在 Facebook 上关注的人、网页和团体的喜欢”[1]。这是一个流行的面试问题。经常被问到的类似问题有:设计 Facebook 的新闻提要,Instagram 的提要,Twitter 的时间线,等等。

理解问题并确定设计范围
第一组澄清问题是为了了解当面试官要求你设计一个新闻源系统时,她的想法是什么。最起码,你应该弄清楚要支持哪些功能。下面是一个应聘者与面试官互动的例子。
应聘者:这是一个移动应用程序吗?还是一个网络应用?或者两者都是? 面试官:都是 应聘者:有哪些重要的功能? 面试官:用户可以发布帖子,并在新闻源页面上看到她朋友的帖子。 应聘者:新闻源是按照逆时针顺序还是任何特定的顺序排序的,比如话题得分?比如说,你的亲密朋友的帖子得分更高。 面试官:为了简单起见,我们假设新闻源是按逆时针顺序排序的。 应聘者:一个用户可以有多少个朋友? 面试官:5000 应聘者:流量是多少? 面试官:1000 万 DAU 应聘者:新闻源可以包含图片、视频,还是只有文字? 面试官:可以。它可以包含媒体文件,包括图片和视频。
现在你已经收集了需求,我们把重点放在设计系统上。
提出高层次的设计并获得认同
该设计分为两个流程:新闻发布和新闻源构建。
- 新闻发布:当一个用户发布了一个帖子,相应的数据被写入缓存和数据库。一个帖子被填充到她朋友的新闻源中。
- 新闻源构建:为简单起见,我们假设新闻源是通过将朋友的帖子按逆时针顺序聚合而构建的。
新闻源 API
新闻源 API 是客户端与服务器通信的主要方式。这些 API 是基于 HTTP 的,允许客户端执行操作,其中包括发布状态、检索新闻源、添加朋友等。我们讨论两个最重要的 API:Feed publishing API 和 News Feed retrieval API。
Feed publishing API 要发布一个帖子,将向服务器发送一个 HTTP POST 请求。该 API 显示如下。
POST /v1/me/feed
- Params:
- content:内容是帖子的文本。
- auth_token:它用于验证 API 请求。
新闻提要检索 API 检索新闻提要的 API 如下所示。
GET /v1/me/feed
- Params:
- auth_token:它用于验证 API 请求。
新闻发布
图 11-2 显示了 feed 发布流程的高层设计。
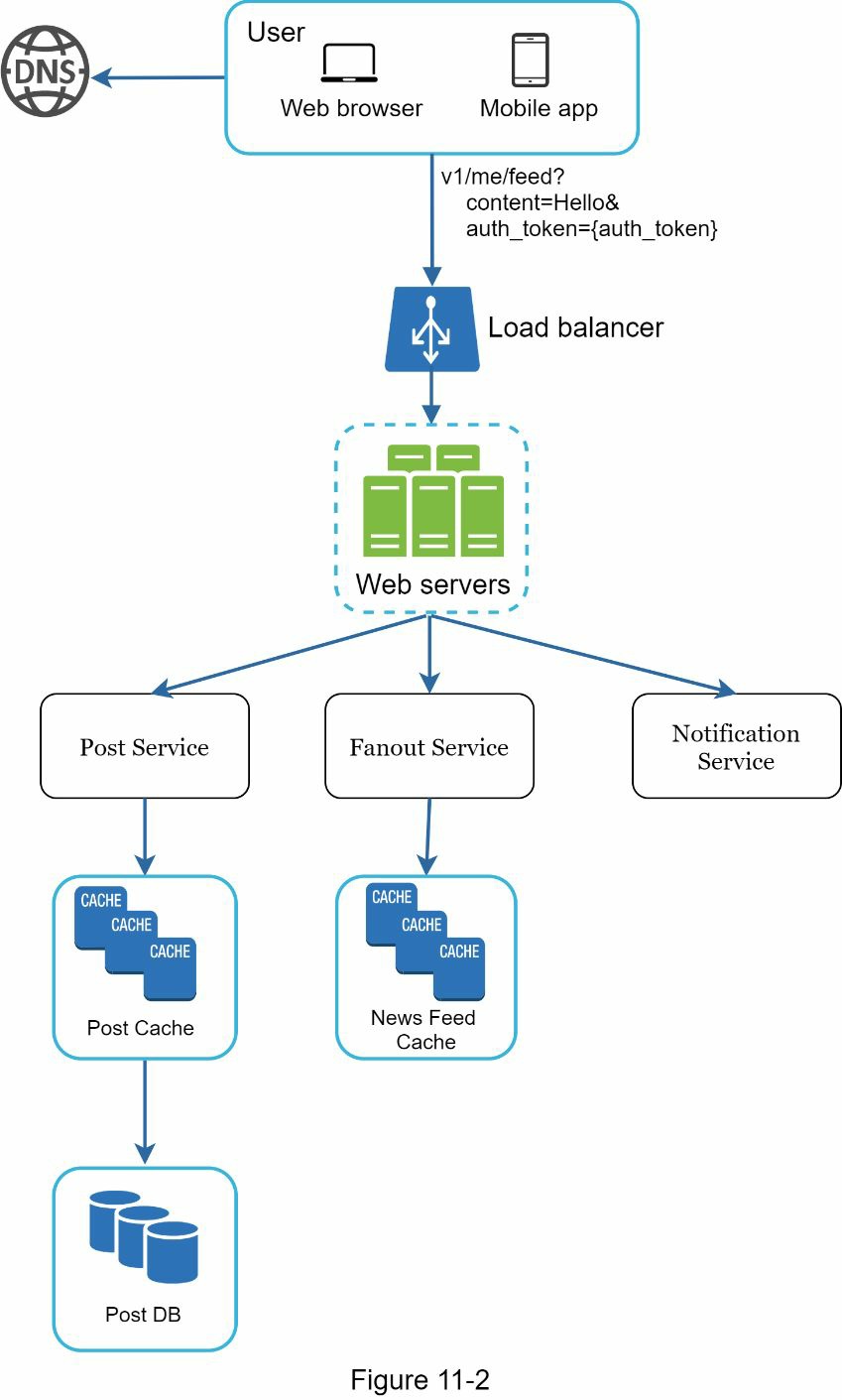
- 用户:一个用户可以在浏览器或移动应用程序上查看新闻提要。一个用户通过 API 发布内容为 “你好"的帖子:/v1/me/feed? content=Hello&auth_token={auth_token}。
- 负载平衡器:将流量分配给网络服务器。
- 网络服务器:网络服务器将流量重定向到不同的内部服务。
- 帖子服务:在数据库和缓存中持久保存帖子。
- Fanout 服务:推送新内容到朋友的新闻源。新闻源数据被存储在缓存中,以便快速检索。
- 通知服务:通知朋友有新内容,并发送推送通知。
新闻源构建
在这一节中,我们将讨论新闻源是如何在幕后构建的。图 11-3 显示了高层设计。

- 用户:一个用户发送了一个请求来检索她的新闻提要。该请求看起来像这样:/v1/me/feed。
- 负载平衡器:负载平衡器将流量重定向到网络服务器。
- 网络服务器:网络服务器将请求路由到新闻传送服务。
- 新闻源服务:新闻源服务从缓存中获取新闻源。
- 新闻源缓存:存储渲染新闻源所需的新闻源 ID。
深入设计
高层设计简要地涵盖了两个流程:Feed 发布和新闻源构建。在这里,我们更深入地讨论这些主题。
深入 Feed 发布
图 11-4 概述了 Feed 发布的详细设计。我们已经讨论了高层设计中的大部分组件,我们将专注于两个组件:网络服务器和 fanout 服务。
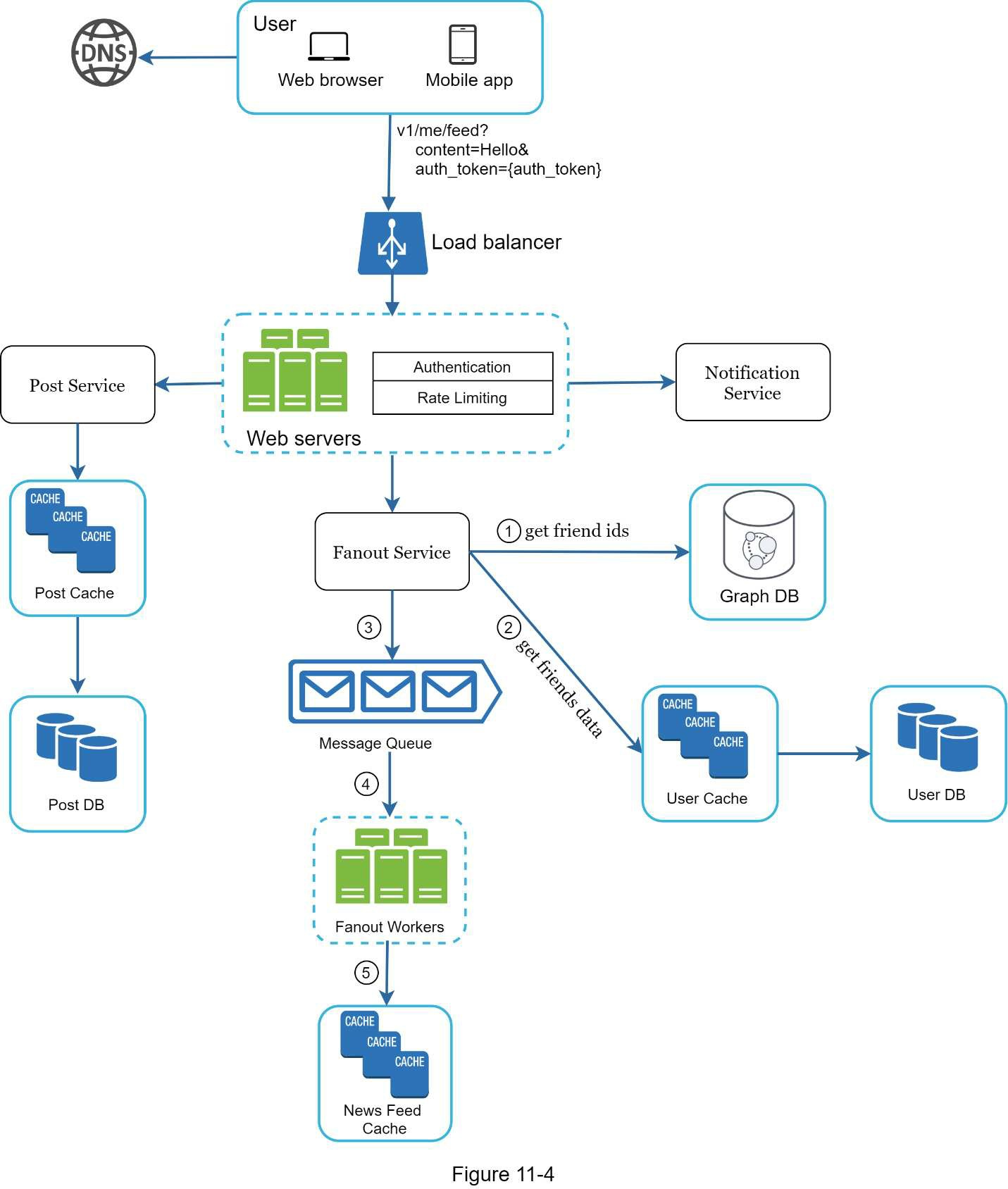
网络服务器
除了与客户进行通信外,网络服务器还执行认证和速率限制。
图 11-4 概述了 Feed 发布的详细设计。我们已经讨论了高层设计中的大部分组件,我们将重点讨论两个组件:网络服务器和 fanout 服务。只有用有效的 auth_token 登录的用户才被允许发帖。系统限制用户在一定时期内的发帖数量,这对于防止垃圾邮件和滥用内容至关重要。
fanout 服务
fanout 是向所有朋友传递一个帖子的过程。两种类型的fanout模式是:写时 fanout(也叫推模式)和读时 fanout(也叫拉模式)。这两种模式都有优点和缺点。我们解释它们的工作流程,并探讨支持我们系统的最佳方法。
写时 fanout。用这种方法,新闻提要在写的时候就已经预先计算好了。一个新的帖子在发布后立即传递到朋友的缓存中。
- 优点
- 新闻源是实时生成的,可以立即推送给朋友。
- 获取新闻源的速度很快,因为新闻源是在写的时候预先计算的。
- 缺点
- 如果一个用户有很多朋友,获取朋友名单并为所有朋友生成新闻源是缓慢和耗时的。这被称为热键问题。
- 对于不活跃的用户或那些很少登录的用户,预先计算新闻源会浪费计算资源。
读取时的 fanout。新闻提要是在阅读时间内产生的。这是一个按需的模式。当用户加载她的主页时,最近的帖子被拉出。
- 优点
- 对于不活跃的用户或那些很少登录的用户,读取时的fanout效果更好,因为它不会在他们身上浪费计算资源。
- 数据不会被推送给朋友,所以不存在热键问题。
- 缺点
- 获取新闻源的速度很慢,因为新闻源不是预先计算的。
我们采用了一种混合方法,以获得两种方法的好处并避免其中的陷阱。由于快速获取新闻源是至关重要的,我们对大多数用户使用推送模式。对于名人或有很多朋友/粉丝的用户,我们让粉丝按需提取新闻内容以避免系统过载。一致性散列是缓解热键问题的一个有用技术,因为它有助于更均匀地分配请求/数据。
让我们仔细看看图 11-5 中所示的fanout服务。
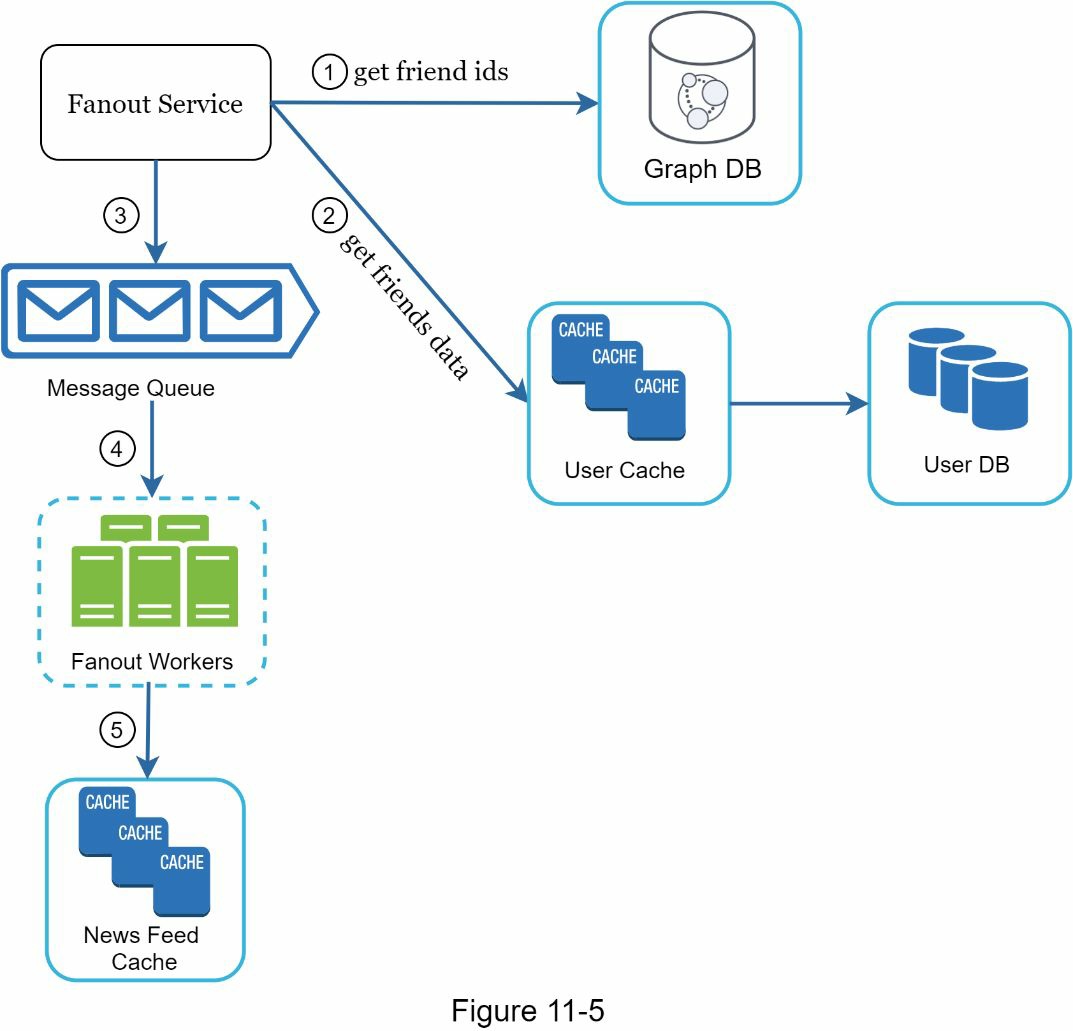
fanout服务的工作方式如下。
- 从图数据库中获取朋友 ID。图形数据库适合于管理朋友关系和朋友推荐。有兴趣的读者希望了解更多关于这个概念的信息,请参考参考资料[2]。
- 从用户缓存中获取朋友信息。然后,系统根据用户设置过滤出朋友。例如,如果你把某人调成静音,她的帖子就不会出现在你的新闻提要中,尽管你们仍然是朋友。帖子可能不显示的另一个原因是,用户可以有选择地与特定的朋友分享信息或对其他人隐藏信息。
- 将好友列表和新帖子的 ID 发送到消息队列中。
- Fanout 工作者从消息队列中获取数据,并将新闻源数据存储在新闻源缓存中。你可以把新闻源缓存看作是一个<post_id, user_id>的映射表。每当有新的帖子,它将被追加到新闻源表中,如图 11-6 所示。如果我们在缓存中存储整个用户和帖子对象,内存消耗会变得非常大。因此,只有 ID 被存储。为了保持较小的内存大小,我们设置了一个可配置的限制。用户在新闻源中滚动浏览成千上万的帖子的机会很小。大多数用户只对最新的内容感兴趣,所以缓存的失误率很低。
- 将<post_id, user_id>存储在新闻源缓冲区。图 11-6 显示了新闻源在缓存中的样子的一个例子。

新闻源检索的深入研究
图 11-7 说明了新闻提要检索的详细设计。
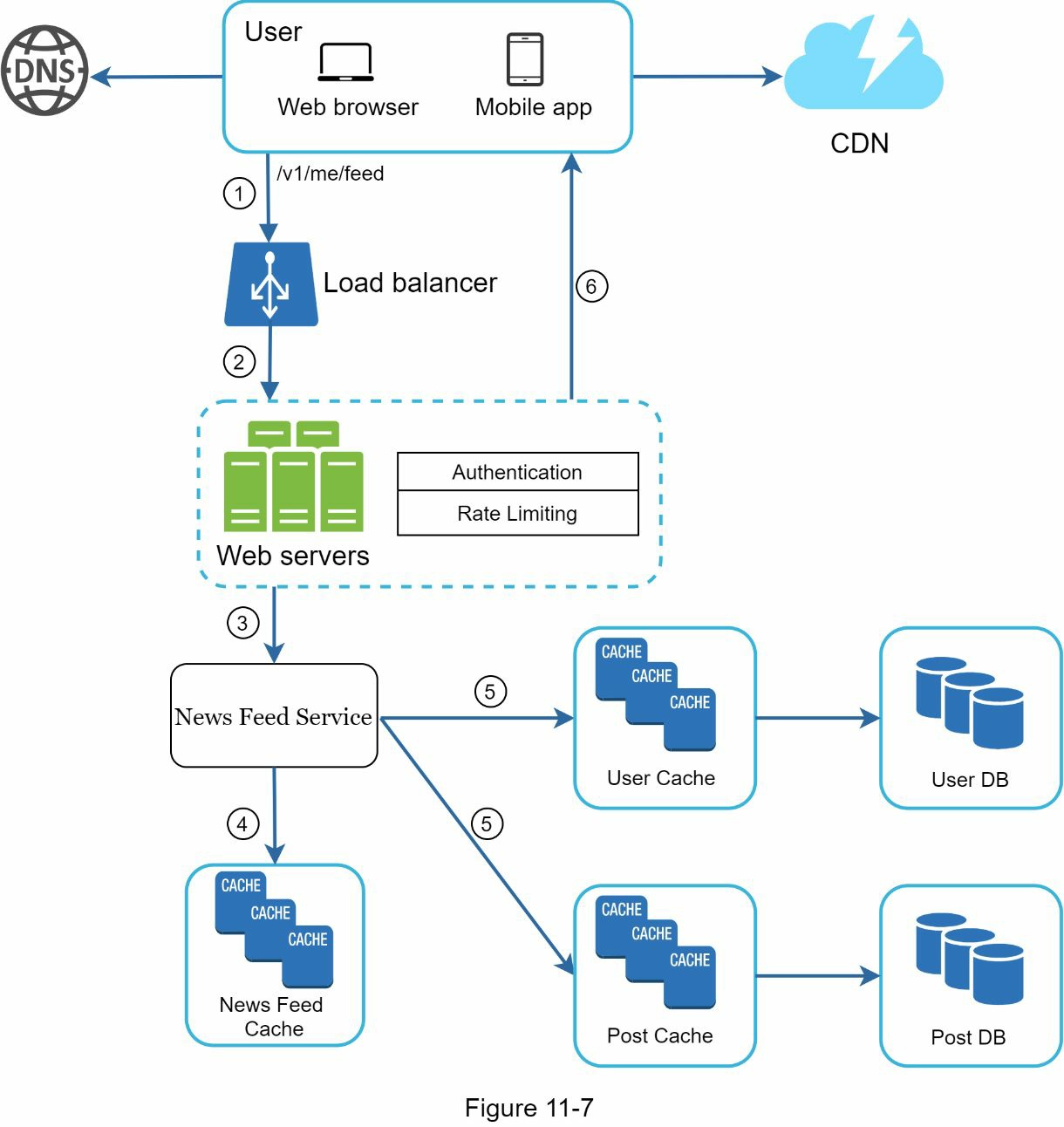
如图 11-7 所示,媒体内容(图片、视频等)被存储在 CDN 中,以便快速检索。让我们看看客户端如何检索新闻提要。
- 一个用户发送一个请求来检索她的新闻提要。该请求看起来像这样。
/v1/me/feed - 负载均衡器将请求重新分配到网络服务器。
- 网络服务器调用新闻源服务以获取新闻源。
- 新闻源服务从新闻源缓存中获得一个列表的帖子 ID。
- 一个用户的新闻提要不仅仅是一个提要 ID 的列表。它包含用户名、个人资料图片、帖子内容、帖子图片等。因此,新闻源服务从缓冲区(用户缓冲区和帖子缓冲区)获取完整的用户和帖子对象,以构建完全混合化的新闻源。
- 完全混合的新闻源以 JSON 格式返回给客户端进行渲染。
缓存架构
缓存对于一个新闻源系统来说是极其重要的。我们将缓存层分为 5 层,如图 11-8 所示。
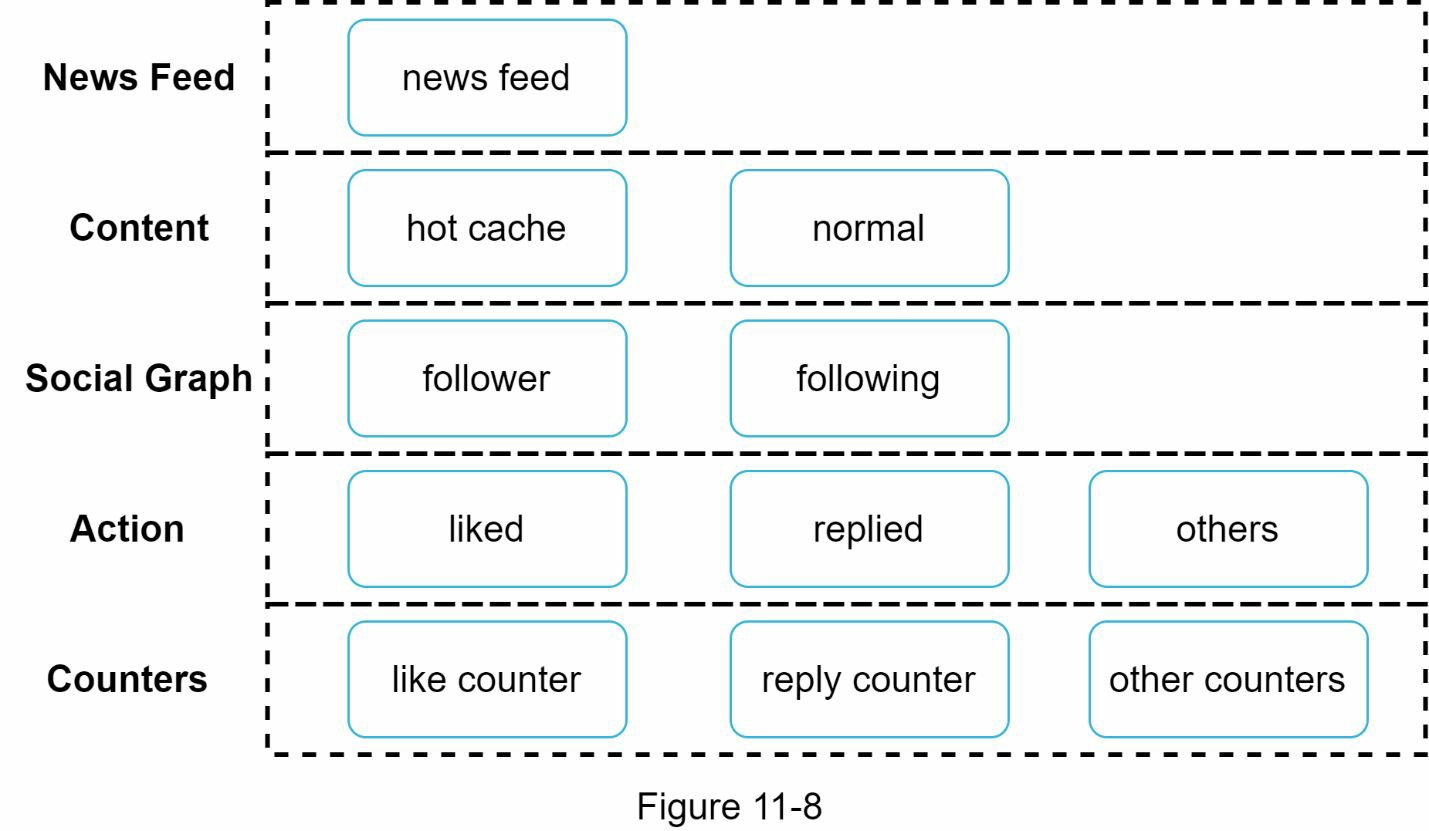
- 新闻提要。它存储新闻提要的 ID。
- 内容。它存储每个帖子的数据。受欢迎的内容被存储在热缓存中。
- 社会图谱。它存储用户关系数据。
- 行动。它存储了关于用户是否喜欢某个帖子、回复某个帖子或对某个帖子采取其他行动的信息。
- 计数器。它存储了喜欢、回复、追随者、关注等的计数器。
总结
在本章中,我们设计了一个新闻源系统。我们的设计包含两个流程:feed 发布和新闻源检索。
像任何系统设计的面试问题一样,没有完美的方法来设计一个系统。每个公司都有其独特的约束,你必须设计一个系统来适应这些约束。了解你的设计和技术选择的权衡是很重要的。如果还有几分钟的时间,你可以谈谈可扩展性问题。为了避免重复讨论,下面只列出高层次的谈话要点。
数据库的扩展。
- 垂直扩展与水平扩展
- SQL vs NoSQL
- 主-从复制
- 读取复制
- 一致性模型
- 数据库分片
其他要点
- 保持网络层的无状态
- 尽可能地缓存数据
- 支持多个数据中心
- 丢掉有消息队列的几个组件
- 监测关键指标。例如,在高峰期的 QPS 和用户刷新他们的新闻提要时的延迟是值得监测的。
祝贺你走到了这一步! 现在给自己拍拍背吧。干得好!
参考资料
Reference materials