设计网页爬虫
在这一章中,我们重点讨论网络爬虫设计:一个有趣的、经典的系统设计面试问题。
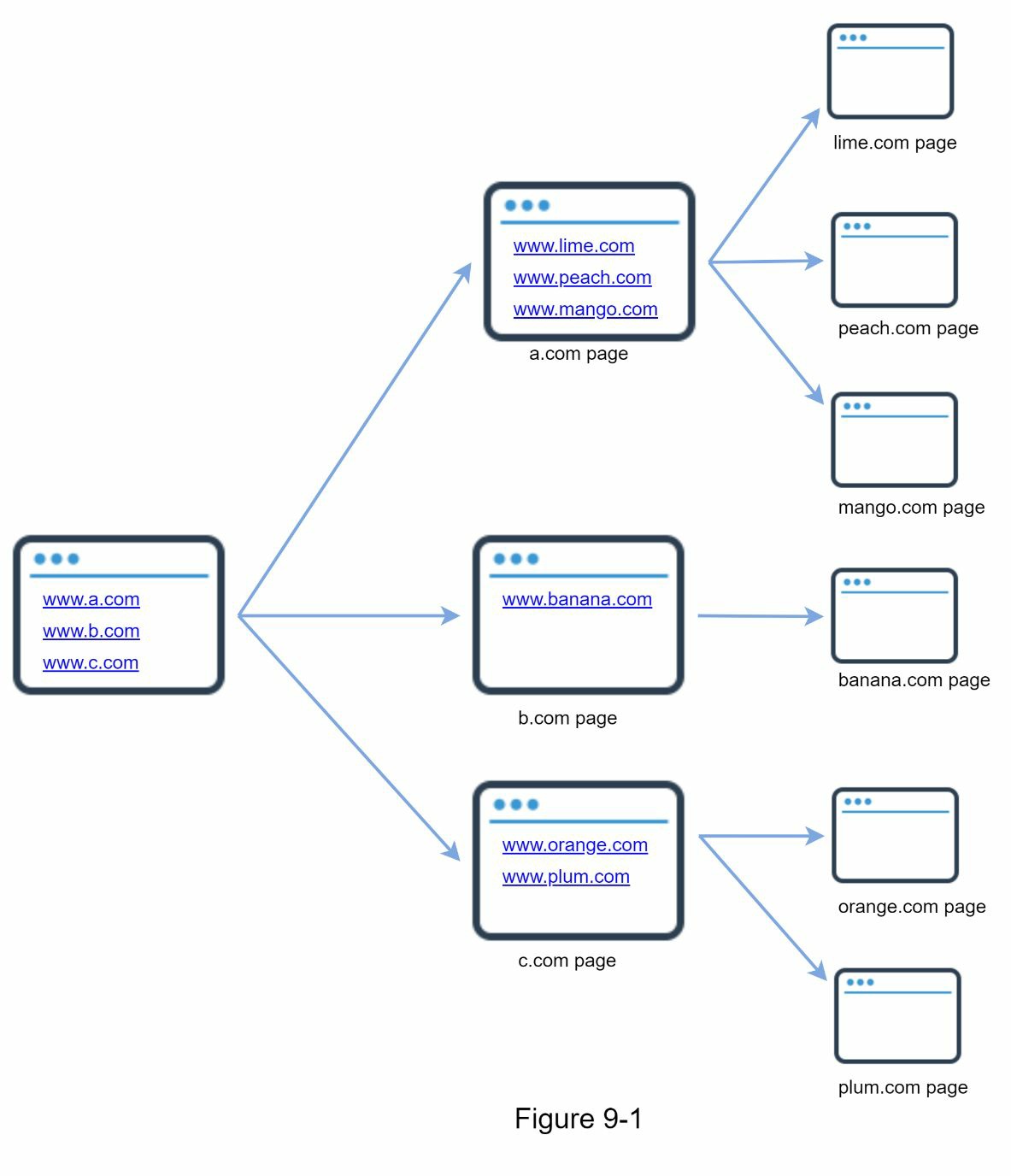
网络爬虫被称为机器人或蜘蛛。它被搜索引擎广泛用于发现网络上新的或更新的内容。内容可以是一个网页、一张图片、一段视频、一个 PDF 文件,等等。网络爬虫从收集一些网页开始,然后跟踪这些网页上的链接来收集新内容。图 9-1 显示了爬虫过程的一个直观例子。
爬虫有许多用途。
- 搜索引擎的索引。这是最常见的使用情况。爬虫收集网页,为搜索引擎创建一个本地索引。例如,Googlebot 是 Google 搜索引擎背后的网络爬虫。
- 网络归档。这是一个从网络上收集信息的过程,以保存数据供将来使用。例如,许多国家图书馆运行爬虫来存档网站。著名的例子是美国国会图书馆[1]和欧盟的网络档案[2]。
- 网络挖掘。网络的爆炸性增长为数据挖掘提供了前所未有的机会。网络挖掘有助于从互联网上发现有用的知识。例如,顶级金融公司使用爬虫下载股东会议和年度报告,以了解公司的关键举措。
- 网络监控。爬虫有助于监测互联网上的版权和商标侵权行为。例如,Digimarc[3]利用爬虫来发现盗版作品和报告。
开发一个网络爬虫的复杂性取决于我们打算支持的规模。它可以是一个小型的学校项目,只需要几个小时就能完成,也可以是一个巨大的项目,需要一个专门的工程团队不断改进。因此,我们将在下面探讨要支持的规模和功能。
理解问题并确定设计范围
网络爬虫的基本算法很简单。
- 给定一组 URLs,下载所有由 URLs 寻址的网页。
- 从这些网页中提取 URLs
- 将新的 URL 添加到要下载的 URL 列表中。重复这 3 个步骤。
网络爬虫的工作是否真的像这种基本算法一样简单?并非如此。设计一个巨大的可扩展的网络爬虫是一项极其复杂的任务。任何人都不可能在面试时间内设计出一个大规模的网络爬虫。在进入设计之前,我们必须问一些问题来了解需求并确定设计范围。
候选人:爬虫的主要目的是什么?是用于搜索引擎索引、数据挖掘,还是其他?
面试官:搜索引擎索引。
应聘者:网络爬虫每月能收集多少个网页?
面试官:10 亿个网页。
应聘者:包括哪些内容类型?只包括 HTML,还是包括其他内容类型,如 PDF 和图片?
面试官:只包括 HTML。
应聘者:我们应该考虑新增加的或编辑过的网页吗?
面试官:是的,我们应该考虑新添加或编辑过的网页。
应聘者:我们是否需要存储从网上抓取的 HTML 网页?
面试官:需要。是的,最多 5 年。
应聘者:我们如何处理有重复内容的网页?
面试官:有重复内容的页面应该被忽略。
以上是一些你可以问面试官的样本问题。理解需求并澄清含糊不清的地方是很重要的。即使你被要求设计一个简单的产品,如网络爬虫,你和你的面试官也可能有不同的假设。
除了与面试官澄清功能外,记下一个好的网络爬虫的以下特点也很重要。
- 可伸缩。网络是非常大的。那里有数十亿的网页。网络爬虫应该使用并行化技术,效率极高。
- 健壮性。网络中充满了陷阱。坏的 HTML、无反应的服务器、崩溃、恶意链接等都很常见。爬虫器必须处理所有这些边缘情况。
- 礼貌性。爬虫不应该在很短的时间间隔内向一个网站发出过多的请求。
- 可扩展性。该系统是灵活的,因此需要最小的变化来支持新的内容类型。例如,如果我们想在将来抓取图像文件,我们应该不需要重新设计整个系统。
粗略估计
下面的估计是基于许多假设,与面试官沟通以保持一致是很重要的。
- 假设每个月有 10 亿个网页被下载。
- QPS:1,000,000,000 / 30 天 / 24 小时 / 3600 秒 =~ 400 页/秒。
- 峰值 QPS = 2 * QPS = 800
- 假设平均网页大小为 500k。
- 10 亿页 x 500k = 每月 500TB 存储量。如果你对数字存储单位不清楚,可以再看一下第二章的 “2 的力量"部分。
- 假设数据存储 5 年,500TB * 12 个月 * 5 年 = 30PB。储存五年的内容需要一个 30PB 的存储。
提出高层次的设计并获得认同
一旦需求明确了,我们就开始进行高层设计。受以前关于网络抓取的研究[4][5]的启发,我们提出了一个高层设计,如图 9-2 所示。
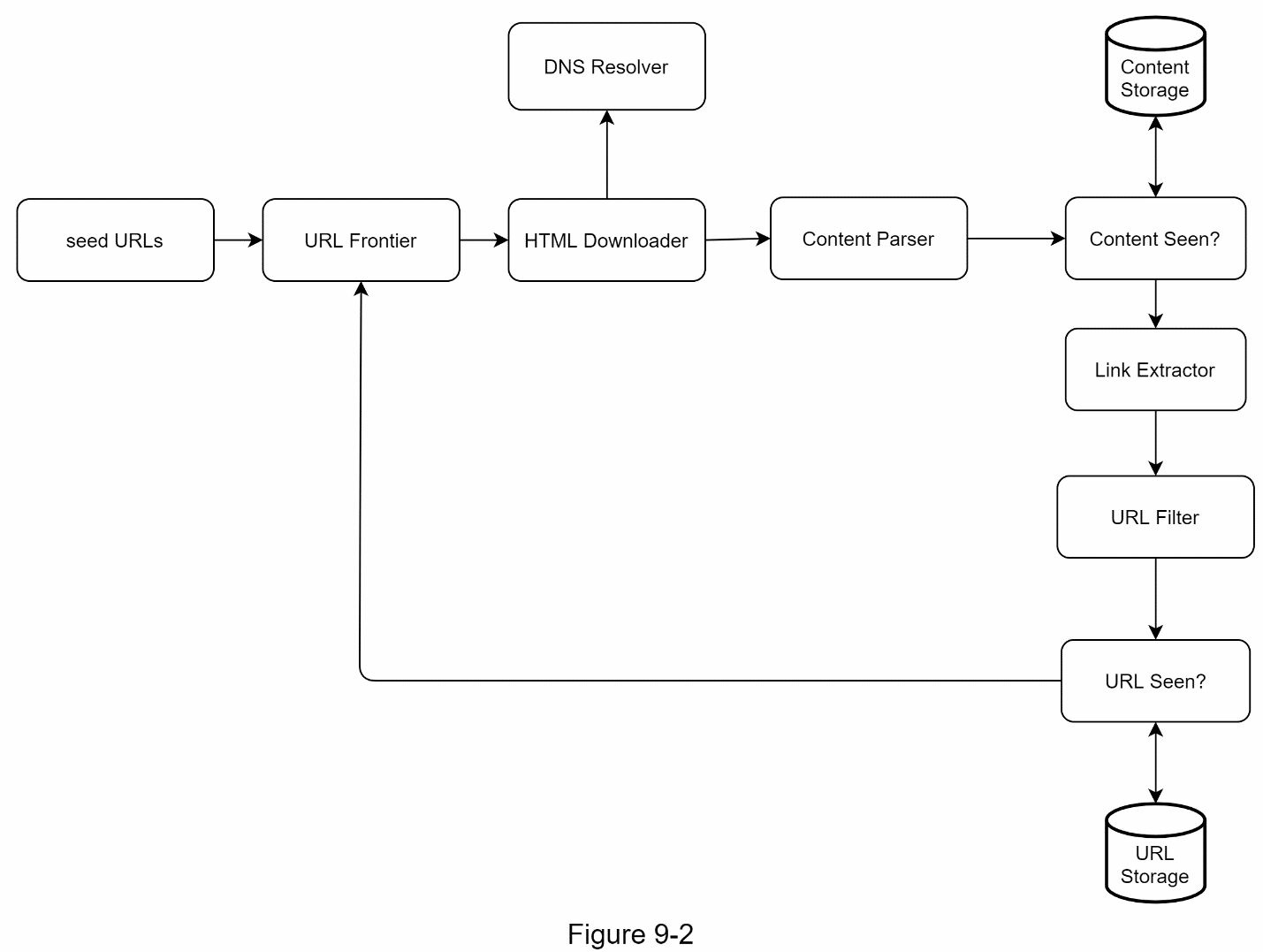
首先,我们探索每个设计组件以了解它们的功能。然后,我们一步一步地考察爬虫的工作流程。
种子网址
一个网络爬虫使用种子网址作为爬虫过程的起点。例如,要抓取一所大学网站的所有网页,选择种子 URL 的一个直观方法是使用该大学的域名。
要抓取整个网络,我们需要创造性地选择种子网址。一个好的种子网址可以作为一个好的起点,爬虫可以利用它来遍历尽可能多的链接。一般的策略是将整个 URL 空间划分为更小的空间。第一个建议的方法是基于地域性,因为不同的国家可能有不同的流行网站。另一种方法是根据主题来选择种子 URL;例如,我们可以将 URL 空间划分为购物、体育、保健等。种子网址的选择是一个开放式的问题。不指望你能给出完美的答案。只要尽力思考就可以了。
URL Frontier
大多数现代网络爬虫将抓取状态分为两种:待下载和已下载。存储待下载的 URL 的组件被称为 URL Frontier。你可以把它称为先进先出(FIFO)队列。关于 URL Frontier 的详细信息,请参考深入研究。
HTML 下载器
HTML 下载器从互联网上下载网页。这些 URL 是由 URL Frontier 提供的。
DNS 解析器
要下载一个网页,URL 必须被翻译成一个 IP 地址。HTML 下载器调用 DNS 解析器来获得 URL 的相应 IP 地址。例如,截至 2019 年 5 月 3 日,URL www.wikipedia.org 被转换为 IP 地址 198.35.26.96。
内容解析器
网页被下载后,必须对其进行解析和验证,因为畸形的网页可能引发问题并浪费存储空间。在抓取服务器中实施内容解析器会减慢抓取过程。因此,内容解析器是一个单独的组件。
看到的内容?
在线研究[6]显示,29%的网页是重复的内容,这可能导致同一内容被多次存储。我们引入 “所见内容 “数据结构,以消除数据冗余并缩短处理时间。它有助于检测以前存储在系统中的新内容。为了比较两个 HTML 文档,我们可以逐个字符进行比较。然而,这种方法既慢又费时,特别是当涉及到数十亿的网页时。完成这项任务的一个有效方法是比较两个网页的哈希值[7]。
内容存储
它是一个用于存储 HTML 内容的存储系统。存储系统的选择取决于诸如数据类型、数据大小、访问频率、寿命等因素。磁盘和内存都可以使用。
- 大多数内容被存储在磁盘上,因为数据集太大,无法装入内存。
- 受欢迎的内容被保存在内存中以减少延迟。
URL 提取器
URL 提取器分析和提取 HTML 页面的链接。图 9-3 显示了一个链接提取过程的例子。通过添加 “https://en.wikipedia.org” 前缀,相对路径被转换为绝对 URL。

URL 过滤器
URL 过滤器排除了某些内容类型、文件扩展名、错误链接和 “黑名单 “网站的 URL。
URL Seen?
“URL Seen?” 是一个数据结构,用于跟踪以前访问过的或已经在 Frontier 中的 URL。“URL Seen?” 有助于避免多次添加相同的 URL,因为这可能会增加服务器负载并导致潜在的无限循环。
布隆过滤器和哈希表是实现 “URL Seen?” 组件的常用技术。我们不会在这里介绍布隆过滤器和哈希表的详细实现。更多信息请参考参考资料[4] [8]。
URL 存储
URL 存储可以存储已经访问过的 URL。
到目前为止,我们已经讨论了每个系统组件。接下来,我们把它们放在一起,解释工作流程。
网络爬虫的工作流程
为了更好地解释工作流程的步骤,在设计图中加入了序列号,如图 9-4 所示。
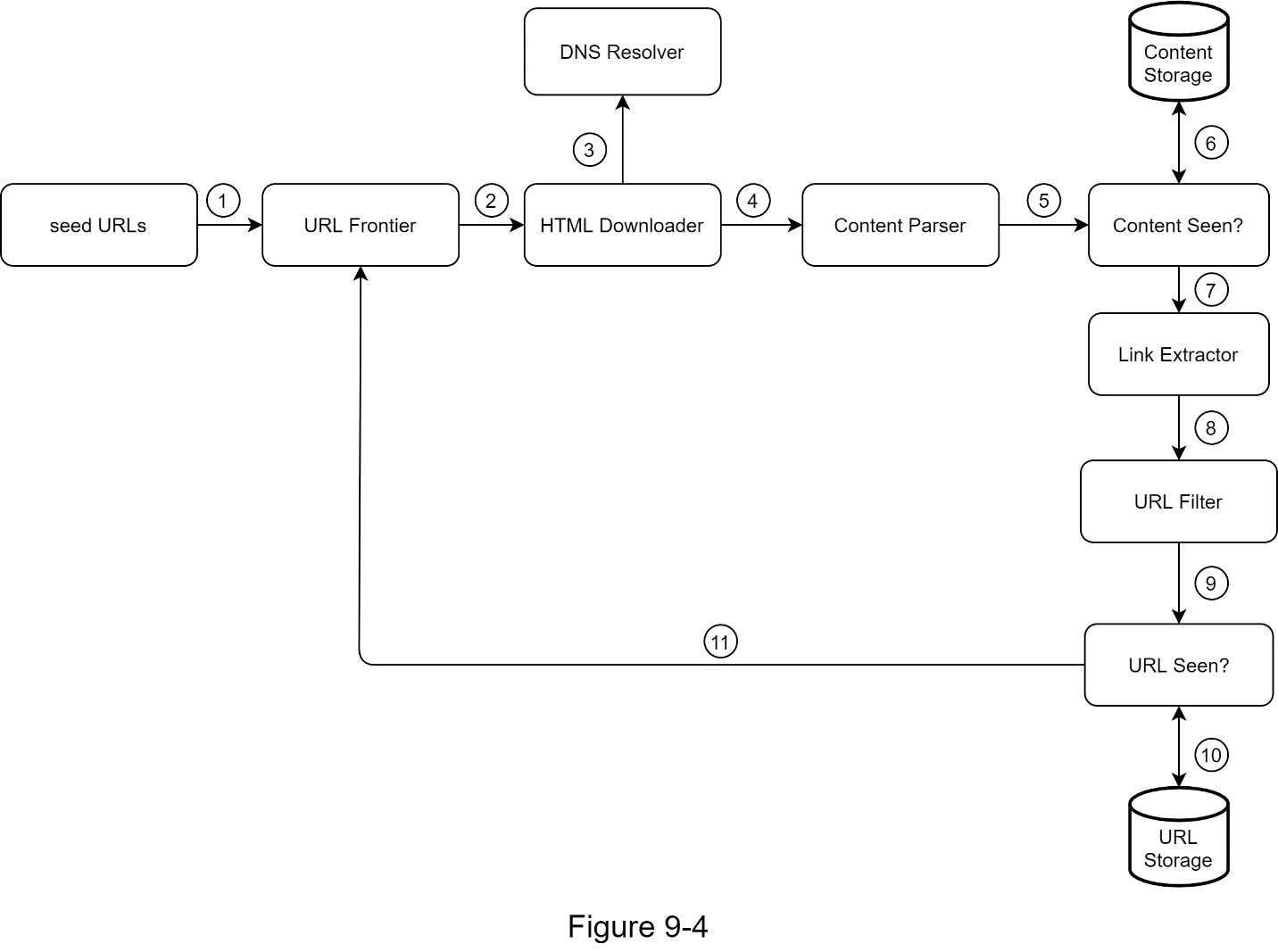
- 第 1 步:在 URL Frontier 中添加种子 URL
- 第 2 步:HTML 下载器从 URL Frontier 中获取 URL 的列表。
- 第 3 步:HTML 下载器从 DNS 解析器获取 URLs 的 IP 地址,并开始下载。
- 第 4 步:内容解析器解析 HTML 页面并检查页面是否畸形。
- 第 5 步:内容被解析和验证后,它被传递给 “Content Seen"组件。
- 第 6 步:“Content Seen"组件检查 HTML 页面是否已经在存储器中。
- 如果它在存储器中,这意味着不同 URL 中的相同内容已经被处理。在这种情况下,该 HTML 页面被丢弃。
- 如果它不在存储器中,则系统以前没有处理过相同的内容。该内容被传递给链接提取器。
- 第 7 步:链接提取器从 HTML 页面中提取链接。
- 第 8 步:提取的链接被传递给 URL 过滤器。
- 第 9 步:在链接被过滤后,它们被传递给 “URL Seen? “组件。
- 第 10 步。“URL Seen “组件检查一个 URL 是否已经在存储中,如果是,它就会在之前被处理,而不需要做任何事情。
- 第 11 步:如果一个 URL 之前没有被处理过,它将被添加到 URL Frontier 中。
设计深究
到现在为止,我们已经讨论了高层设计。接下来,我们将深入讨论最重要的构建组件和技术。
- 深度优先搜索(DFS)与广度优先搜索(BFS)的对比
- URL 前沿阵地
- HTML 下载器
- 健壮性
- 可扩展性
- 检测并避免有问题的内容
DFS vs BFS
你可以把网络想象成一个有向图,其中网页作为节点,超链接(URL)作为边。抓取过程可以被视为从一个网页到其他网页的有向图的遍历。两种常见的图形遍历算法是 DFS 和 BFS。然而,DFS 通常不是一个好的选择,因为 DFS 的深度可能很深。
BFS 通常被网络爬虫使用,由先进先出(FIFO)队列实现。在先进先出队列中,URL 是按照它们被排队的顺序进行排队的。然而,这种实现方式有两个问题。
- 来自同一网页的大多数链接都被链接回同一主机。在图 9-5 中,wikipedia.com 的所有链接都是内部链接,使得爬虫忙于处理来自同一主机(wikipedia.com)的 URL。当爬虫试图平行下载网页时,维基百科服务器将被请求淹没。这被认为是 “不礼貌的”。

标准的 BFS 没有考虑到 URL 的优先级。网络很大,不是每个页面都有相同的质量和重要性。因此,我们可能希望根据页面排名、网络流量、更新频率等来确定 URL 的优先次序。
URL frontier
URL frontier 有助于解决这些问题。URL frontier 是一个数据结构,存储要下载的 URL。URL frontier 是确保礼貌性、URL 优先性和实效性的一个重要组成部分。在参考资料中提到了一些关于 URL frontier 的值得注意的论文[5][9]。这些论文的结论如下。
礼貌性
一般来说,网络爬虫应该避免在短时间内向同一主机服务器发送太多的请求。发送过多的请求被认为是 “不礼貌的”,甚至被视为拒绝服务(DOS)攻击。例如,在没有任何约束的情况下,爬虫每秒可以向同一个网站发送成千上万的请求。这可能使网络服务器不堪重负。
执行礼貌的一般想法是,每次从同一主机下载一个页面。在两个下载任务之间可以增加一个延迟。礼貌性约束是通过维护网站主机名到下载(工作者)线程的映射来实现的。每个下载者线程都有一个单独的 FIFO 队列,并且只下载从该队列中获得的 URLs。图 9-6 显示了管理礼貌的设计。
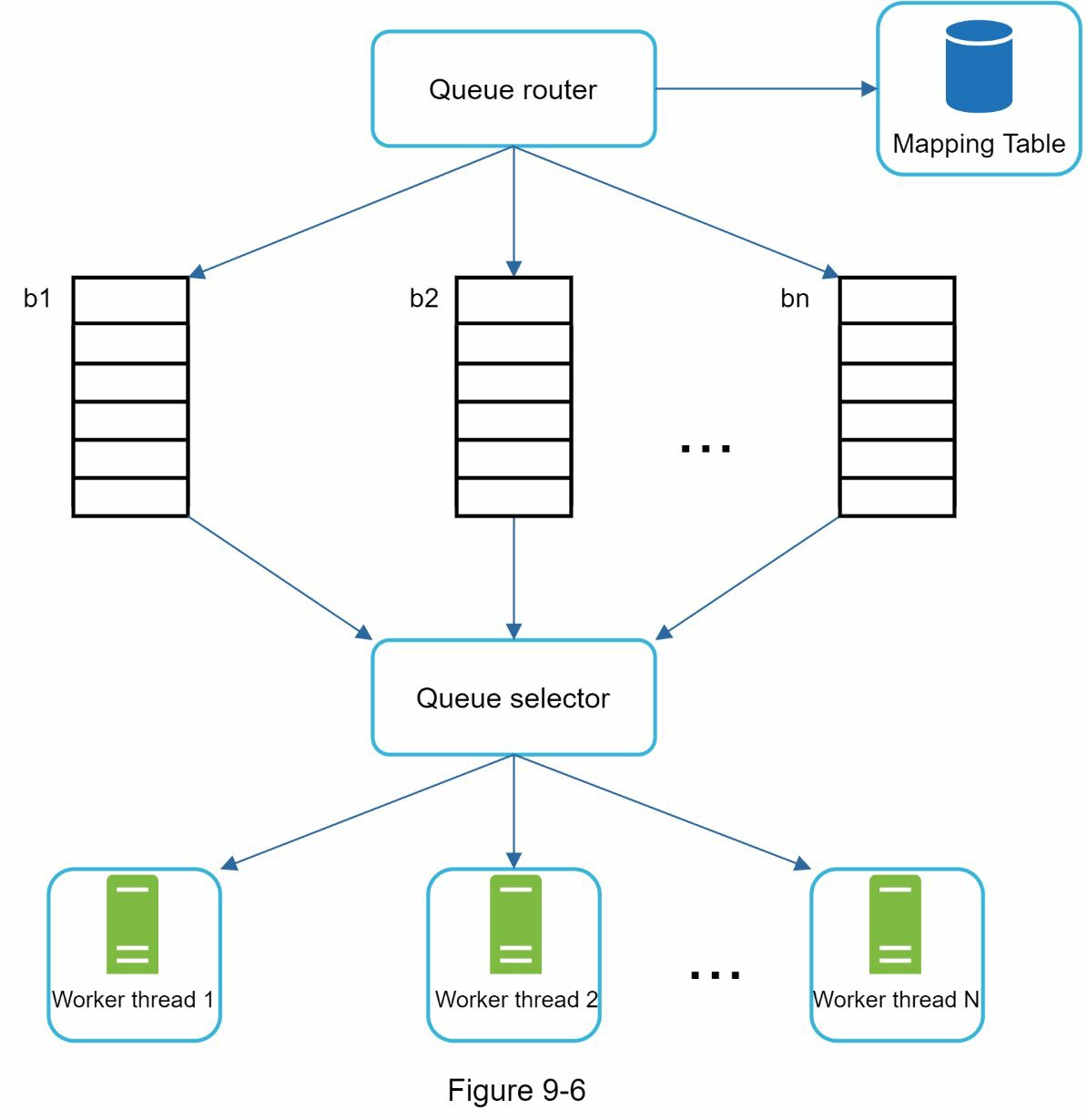
- 队列路由器。它确保每个队列(b1,b2,…bn)只包含来自同一主机的 URL。
- 映射表。它将每个主机映射到一个队列。
- FIFO 队列 b1、b2 到 bn:每个队列包含来自同一主机的 URL。
- 队列选择器。每个工作线程都被映射到一个先进先出队列,它只从该队列下载 URL。队列选择逻辑是由队列选择器完成的。
- 工作线程 1 至 N。一个工作线程从同一主机逐一下载网页。在两个下载任务之间可以添加一个延迟

优先级
一个关于苹果产品的讨论论坛上的随机帖子与苹果主页上的帖子具有非常不同的权重。尽管它们都有 “苹果 “这个关键词,但爬虫首先抓取苹果主页是明智之举。
我们根据有用性来确定 URL 的优先级,有用性可以通过 PageRank[10]、网站流量、更新频率等来衡量。“Prioritizer “是处理 URL 优先级的组件。请参考参考资料[5][10],了解关于这个概念的深入信息。
图 9-7 显示了管理 URL 优先权的设计。
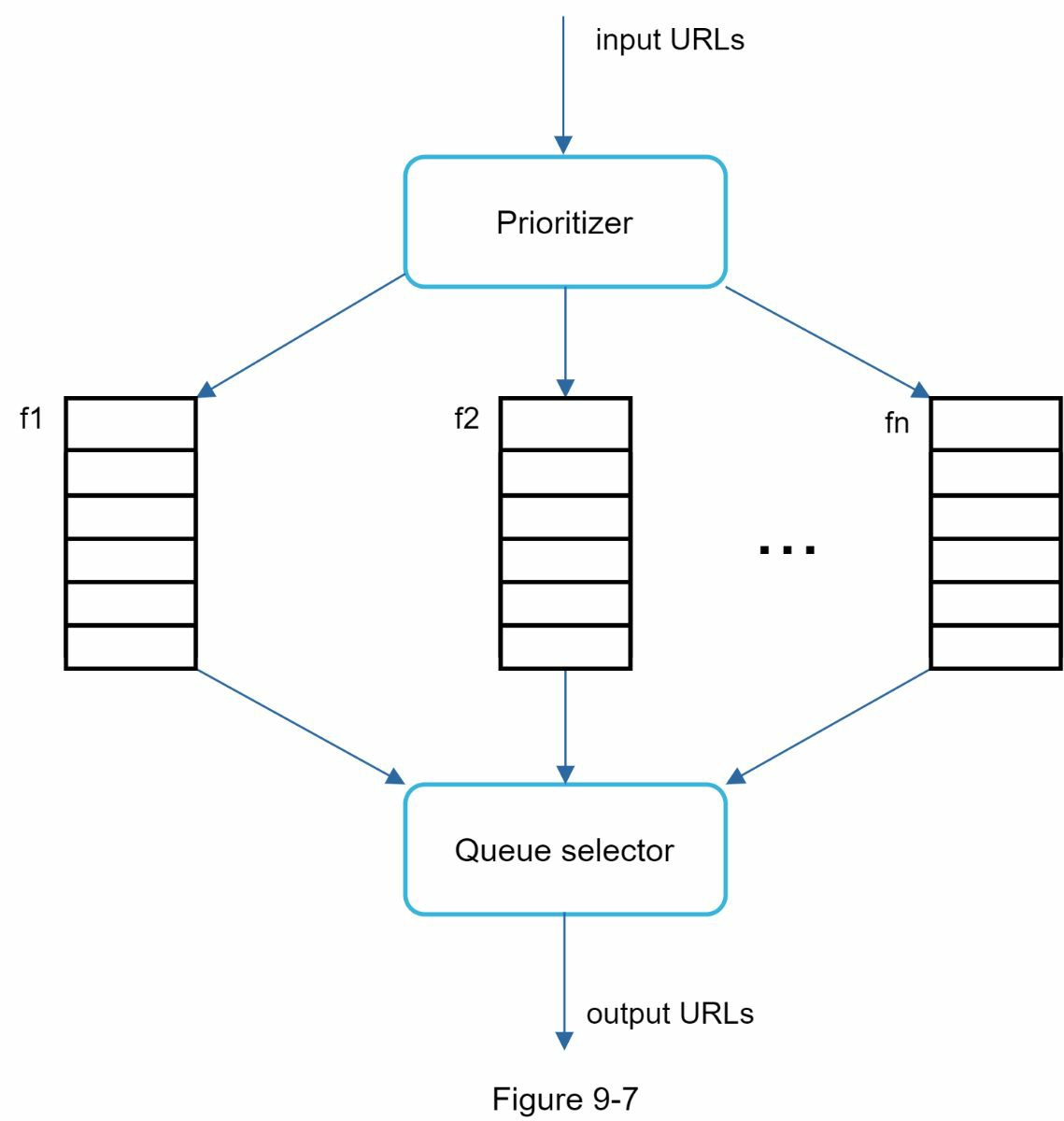
- 优先排序器。它将 URL 作为输入并计算出优先级。
- 队列 f1 至 fn:每个队列都有一个分配的优先级。具有高优先级的队列以更高的概率被选中。
- 队列选择器。随机选择一个队列,偏向于具有较高优先级的队列。
图 9-8 展示了 URL frontier 设计,它包含两个模块。
- 前队列:管理优先次序
- 后队列:管理礼貌性

保持更新
网页在不断被添加、删除和编辑。网络爬虫必须定期重新抓取下载的网页,以保持我们的数据集是新的。重新抓取所有的 URL 是非常耗时和耗资源的。以下是一些优化实效性的策略。
- 根据网页的更新历史重新抓取。
- 对 URL 进行优先排序,首先更频繁地重新抓取重要网页。
URL Frontier 存储
在现实世界的搜索引擎的抓取中,url frontier 中的 URL 数量可能是数以亿计的[4]。把所有的东西都放在内存中既不耐用也不具有可扩展性。把所有东西都放在磁盘里也不可取,因为磁盘很慢;而且它很容易成为抓取的瓶颈。
我们采用了一种混合方法。大部分的 URL 都存储在磁盘上,所以存储空间不是问题。为了减少从磁盘上读取和写入磁盘的成本,我们在内存中维护缓冲区,用于 enqueue/dequeue 操作。缓冲区中的数据会定期写入磁盘。
HTML 下载器
HTML 下载器使用 HTTP 协议从互联网上下载网页。在讨论 HTML 下载器之前,我们先看一下 Robots 排除协议。
Robots.txt
Robots.txt,称为 Robots 排除协议,是网站用来与爬虫通信的标准。它规定了允许爬虫下载哪些页面。在试图爬虫一个网站之前,爬虫应首先检查其相应的 robots.txt,并遵守其规则。
为了避免重复下载 robots.txt 文件,我们对该文件的结果进行了缓存。该文件会定期下载并保存到缓存中。下面是取自 https://www.amazon.com/robots.txt 的 robots.txt 文件的一个片段。一些目录,如 creatorhub,是不允许谷歌机器人进入的。
User-agent: Googlebot
Disallow: /creatorhub/*
Disallow: /rss/people/*/reviews
Disallow: /gp/pdp/rss/*/reviews
Disallow: /gp/cdp/member-reviews/
Disallow: /gp/aw/cr/
除了 robots.txt,性能优化是我们将涵盖的 HTML 下载器的另一个重要概念。
性能优化
下面是 HTML 下载器的性能优化手段。
- 分布式爬虫
为了实现高性能,抓取工作被分配到多个服务器,每个服务器运行多个线程。URL 空间被分割成更小的部分;因此,每个下载器负责 URL 的一个子集。图 9-9 显示了一个分布式抓取的例子。

- 缓存 DNS 解析器
DNS 解析器是爬虫的一个瓶颈,因为由于许多 DNS 接口的同步性,DNS 请求可能需要时间。DNS 的响应时间从 10ms 到 200ms 不等。一旦爬虫线程对 DNS 进行了请求,其他线程就会被阻断,直到第一个请求完成。维护我们的 DNS 缓存以避免频繁调用 DNS 是一种有效的速度优化技术。我们的 DNS 缓存保持域名到 IP 地址的映射,并通过 cron 作业定期更新。
- 地域性
按地理分布抓取服务器。当爬虫服务器离网站主机较近时,爬虫者会经历更快的下载时间。设计定位适用于大多数系统组件:抓取服务器、缓存、队列、存储等。
- 短暂的超时
有些网站服务器响应缓慢,或者根本不响应。为了避免漫长的等待时间,规定了一个最大的等待时间。如果一个主机在预定的时间内没有反应,爬虫就会停止工作,抓取其他一些网页。
健壮性
除了性能优化,健壮性也是一个重要的考虑因素。我们提出一些方法来提高系统的健壮性。
- 一致性散列:这有助于在下载者之间分配负载。一个新的下载器服务器可以使用一致的散列法添加或删除。更多细节请参考第五章:设计一致的散列。
- 保存抓取状态和数据。为了防止故障,爬行状态和数据被写入一个存储系统。通过加载保存的状态和数据,可以很容易地重新启动被破坏的爬行。
- 异常处理。在一个大规模的系统中,错误是不可避免的,而且很常见。爬虫必须优雅地处理异常,而不会使系统崩溃。
- 数据验证。这是防止系统错误的一个重要措施。
可扩展性
由于几乎每个系统都在不断发展,设计目标之一是使系统足够灵活,以支持新的内容类型。抓取器可以通过插入新的模块来扩展。图 9-10 显示了如何添加新模块。
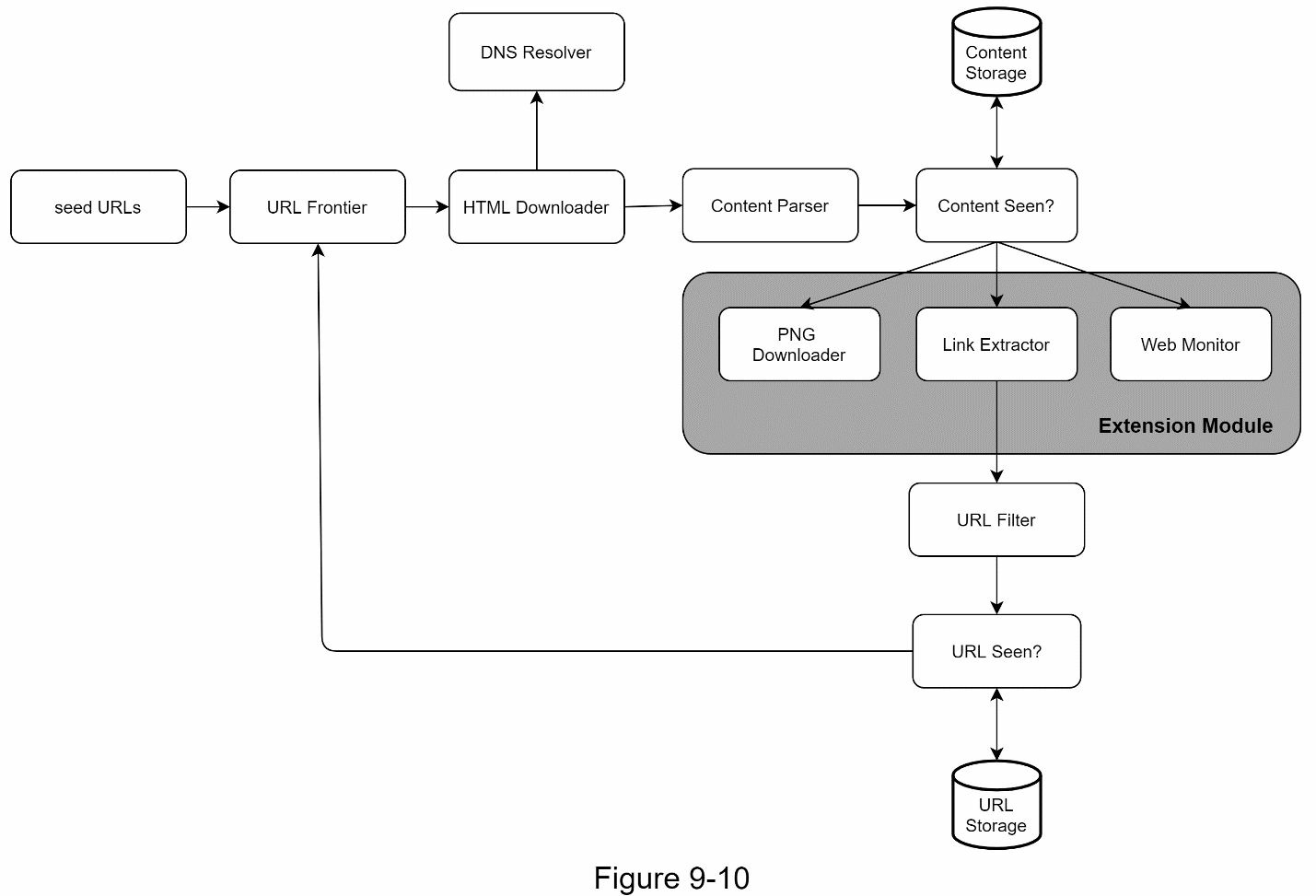
- PNG 下载器模块被插入以下载 PNG 文件。
- 网络监控模块的加入是为了监控网络,防止版权和商标侵权。
检测并避免有问题的内容
本节讨论了检测和预防冗余、无意义或有害内容的问题。
- 冗余内容
如前所述,近 30%的网页是重复的。哈希值或校验值有助于检测重复内容[11]。
- 蜘蛛陷阱
蜘蛛陷阱是一个导致爬虫处于无限循环的网页。例如,一个无限深的目录结构列举如下:
www.spidertrapexample.com/foo/bar/foo/bar/foo/bar/…
这样的蜘蛛陷阱可以通过为 URLs 设置最大长度来避免。然而,没有一个放之四海而皆准的解决方案来检测蜘蛛陷阱。含有蜘蛛陷阱的网站很容易被识别,因为在这类网站上发现的网页数量异常多。很难开发出避免蜘蛛陷阱的自动算法;然而,用户可以手动验证和识别蜘蛛陷阱,并将这些网站从爬虫中排除,或应用一些定制的 URL 过滤器。
- 数据噪音
有些内容几乎没有价值,如广告、代码片段、垃圾网址等。这些内容对爬虫没有用处,如果可能的话,应将其排除。
总结
在这一章中,我们首先讨论了一个好的爬虫的特征:可扩展性、礼貌性、可扩展性和健壮性。然后,我们提出了一个设计,并讨论了关键的组成部分。构建一个可扩展的网络爬虫并不是一件微不足道的事情,因为网络是非常大的,而且充满了陷阱。尽管我们已经涵盖了许多主题,但仍然遗漏了许多相关的谈话内容。
- 服务器端渲染。众多网站使用 JavaScript、AJAX 等脚本来产生链接。如果我们直接下载和解析网页,我们将无法检索动态生成的链接。为了解决这个问题,我们在解析网页之前先进行服务器端的渲染(也叫动态渲染)[12]。
- 过滤掉不需要的页面。由于存储容量和抓取资源有限,反垃圾邮件组件有利于过滤掉低质量和垃圾邮件页面[13] [14]。
- 数据库复制和分片。复制和分片等技术被用来提高数据层的可用性、可扩展性和可靠性。
- 横向扩展。对于大规模的抓取,需要数百甚至数千台服务器来执行下载任务。关键是要保持服务器的无状态。
- 可用性、一致性和可靠性。这些概念是任何大型系统成功的核心。我们在第 1 章中详细讨论了这些概念。刷新你对这些主题的记忆。
- 分析。收集和分析数据是任何系统的重要组成部分,因为数据是微调的关键成分。
恭喜你走到这一步! 现在给自己拍拍胸脯吧。干得好!
参考资料
[1] US Library of Congress
[2] EU Web Archive
[3] Digimarc
[4] Heydon A., Najork M. Mercator: A scalable, extensible web crawler World Wide Web, 2 (4) (1999), pp. 219-229
[5] By Christopher Olston, Marc Najork: Web Crawling
[6] 29% Of Sites Face Duplicate Content Issues
[7] Rabin M.O., et al. Fingerprinting by random polynomials Center for Research in Computing Techn., Aiken Computation Laboratory, Univ. (1981)
[8] B. H. Bloom, “Space/time trade-offs in hash coding with allowable errors,” Communications of the ACM, vol. 13, no. 7, pp. 422–426, 1970.
[9] Donald J. Patterson, Web Crawling
[10] L. Page, S. Brin, R. Motwani, and T. Winograd, “The PageRank citation ranking: Bringing order to the web,” Technical Report, Stanford University, 1998.
[11] Burton Bloom. Space/time trade-offs in hash coding with allowable errors. Communications of the ACM, 13(7), pages 422–426, July 1970.
[12] Google Dynamic Rendering
[13] T. Urvoy, T. Lavergne, and P. Filoche, “Tracking web spam with hidden style similarity,” in Proceedings of the 2nd International Workshop on Adversarial Information Retrieval on the Web, 2006.
[14] H.-T. Lee, D. Leonard, X. Wang, and D. Loguinov, “IRLbot: Scaling to 6 billion pages and beyond,” in Proceedings of the 17th International World Wide Web Conference, 2008.