在分布式系统中设计一个唯一 ID 生成器
在本章中,你被要求设计一个分布式系统中的唯一 ID 生成器。你的第一个想法可能是在传统的数据库中使用一个带有自动增加属性的主键。然而,auto_increment 在分布式环境中不起作用,因为单个数据库服务器不够大,以最小的延迟在多个数据库中生成唯一的 ID 是具有挑战性的。
这里有几个唯一 ID 的例子。
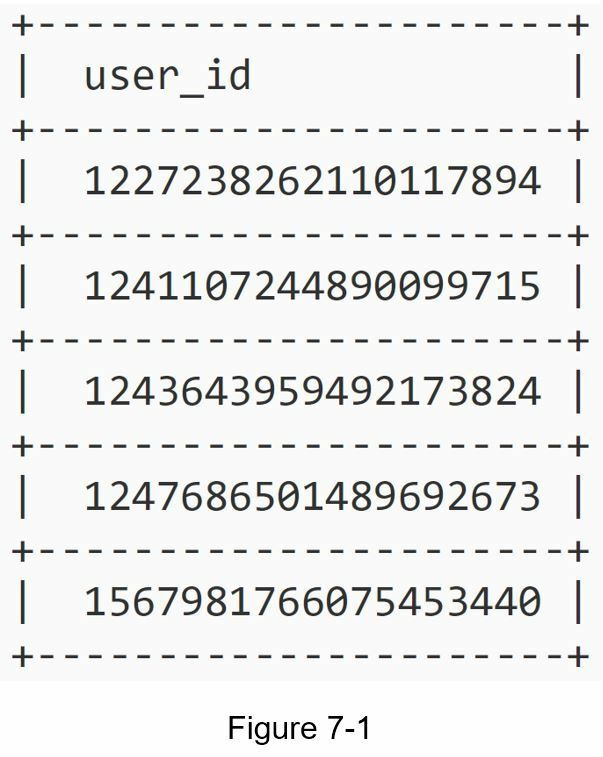
了解问题并确定设计范围
提出明确的问题是解决任何系统设计面试问题的第一步。下面是一个候选人与面试官互动的例子。
候选人:唯一 ID 的特点是什么?
面试官:ID 必须是唯一的,而且是可排序的。
候选者:对于每条新记录,ID 是否递增 1?
面试官:ID 按时间递增,但不一定只按 1 递增。在晚上创建的 ID 比同一天早上创建的 ID 要大。
候选人:ID 是否只包含数值?
面试官:是的,这是对的。
候选热:ID 的长度要求是什么?
面试官:ID 最长 64 位。
候选热:系统的规模是多少?
面试官:系统应该能够每秒生成 10,000 个 ID。
以上是一些你可以问面试官的样本问题。理解需求并澄清模糊之处非常重要。对于这个面试问题,要求列举如下。
- ID 必须是唯一的。
- ID 只能是数值。
- IDs 最长 64 位的。
- IDs 按日期排序。
- 有能力每秒产生超过 10,000 个唯一的 ID。
提出高层次的设计并获得认同
在分布式系统中,可以使用多种选项来生成唯一的 ID。我们考虑的选项是。
- 多主机复制
- 通用唯一标识符 UUID
- Ticket server
- Twitter Snowflake
让我们来看看他们中的每一个,他们是如何工作的,以及每个选项的优点/缺点。
多主机复制
如图 7-2 所示,第一个方法是多主机复制。
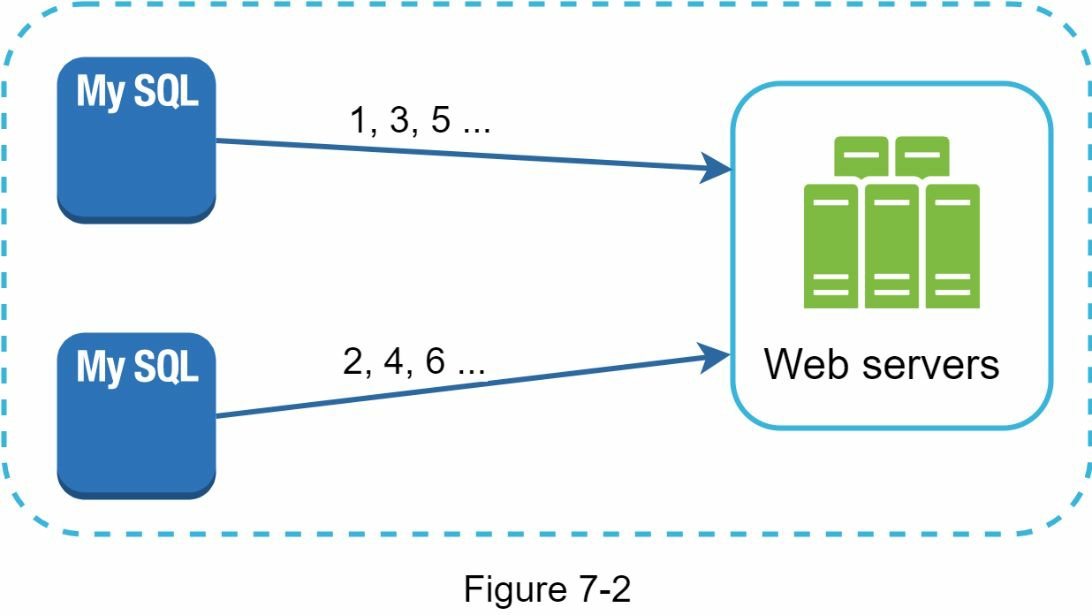
这种方法使用了数据库的自动递增功能。我们不是将下一个 ID 增加 1,而是增加 k,其中 k 是使用中的数据库服务器的数量。如图 7-2 所示,要生成的下一个 ID 等于同一服务器中的上一个 ID 加 2。这解决了一些可扩展性问题,因为 ID 可以随着数据库服务器的数量而扩展。然而,这种策略有一些主要的缺点。
- 很难在多个数据中心中进行扩展
- 在多个服务器上,ID 不会随着时间而上升。
- 当一个服务器被添加或删除时,它不能很好地扩展。
UUID
UUID 是另一种获得唯一 ID 的简单方法。UUID 是一个 128 位的数字,用于识别计算机系统中的信息。UUID 重复的概率非常低。引自维基百科,“在每秒产生 10 亿个 UUIDs 大约 100 年后,创造一个重复的概率会达到 50%” [1]。
这里有一个 UUID 的例子:09c93e62-50b4-468d-bf8a-c07e1040bfb2。UUID 可以独立生成,不需要服务器之间的协调。图 7-3 介绍了 UUIDs 的设计。

在这种设计中,每个网络服务器包含一个 ID 生成器,一个网络服务器负责独立生成 ID。
- 优点。
- 生成 UUID 很简单。不需要服务器之间的协调,所以不会有任何同步的问题。
- 该系统很容易扩展,因为每个网络服务器负责生成他们所消费的 ID。ID 生成器可以很容易地与网络服务器一起扩展。
- 缺点。
- ID 的长度是 128 位,但我们的要求是 64 位。
- ID 不会随着时间的推移而增加。
- ID 可能是非数字性的。
Ticket Server
Ticket server 器是产生唯一 ID 的另一种有趣的方式。Flicker 开发了 Ticket server 器来生成分布式主键[2]。值得一提的是,该系统是如何工作的。
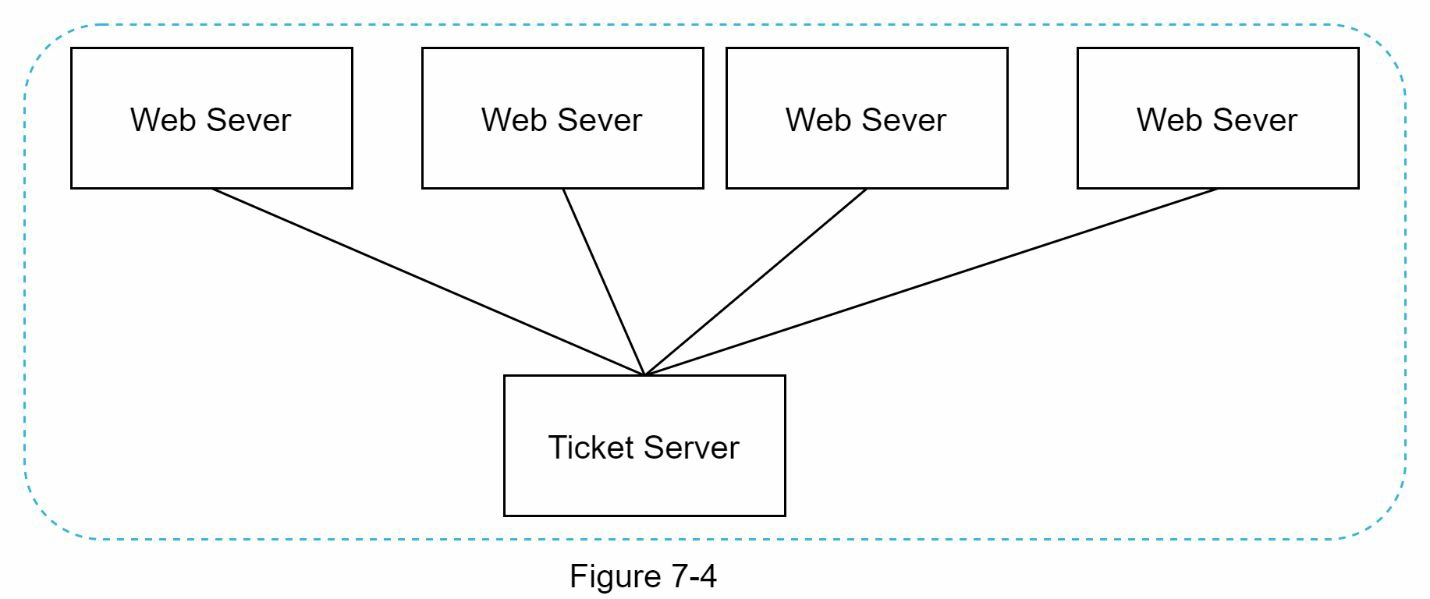
这个想法是在一个单一的数据库服务器(Ticket Server)中使用一个集中的自动增量功能。要了解更多这方面的信息,请参考 flicker 的工程博客文章[2]。
- 优点。
- 数值化的 ID。
- 它很容易实现,而且适用于中小规模的应用。
- 缺点:
- 单点故障。单一的 Ticket server 意味着如果 Ticket server 发生故障,所有依赖它的系统都将面临问题。为了避免单点故障,我们可以设置多个票务服务器。然而,这将引入新的挑战,如数据同步。
Twitter snowflake
上面提到的方法给了我们一些关于不同的 ID 生成系统如何工作的想法。然而,它们都不符合我们的具体要求;因此,我们需要另一种方法。Twitter 的唯一 ID 生成系统 “snowflake”[3]很有启发性,可以满足我们的要求。
分而治之是我们的朋友。我们不是直接生成一个 ID,而是将一个 ID 分成不同的部分。图 7-5 显示了一个 64 位 ID 的布局。

下面对每个部分进行解释。
- 符号位。1 位。它将永远是 0。 这是保留给未来使用的。它有可能被用来区分有符号和无符号的数字。
- 时间戳。41 位。自纪元或自定义纪元以来的毫秒。我们使用 Twitter snowflake 的默认纪元 1288834974657,相当于 2010 年 11 月 4 日,01:42:54 UTC。
- 数据中心 ID:5 位,这给了我们 2 ^ 5 = 32 个数据中心。
- 机器 ID:5 位,每个数据中心有 2 ^ 5 = 32 台机器。
- 序列号:12 位。对于在该机器/进程上产生的每一个 ID,序列号都会增加 1,该号码每隔一毫秒重置为 0。
设计深究
在高层设计中,我们讨论了在分布式系统中设计一个独特的 ID 生成器的各种方案。我们确定了一种基于 Twitter snowflake ID 生成器的方法。让我们深入了解一下这个设计。为了唤起我们的记忆,下面重新列出了设计图。

数据中心 ID 和机器 ID 是在启动时选择的,一般在系统运行后就固定下来。数据中心 ID 和机器 ID 的任何变化都需要仔细审查,因为这些数值的意外变化会导致 ID 冲突。时间戳和序列号是在 ID 生成器运行时生成的。
时间戳
最重要的 41 位组成了时间戳部分。由于时间戳随时间增长,ID 可按时间排序。图 7-7 显示了一个二进制表示法转换为 UTC 的例子。你也可以用类似的方法将 UTC 转换回二进制表示法。

可以用 41 位表示的最大时间戳是
2 ^ 41 - 1 = 2199023255551 毫秒(ms),这给了我们。~ 69 年=2199023255551 毫秒/1000 秒/365 天/24 小时/3600 秒。这意味着 ID 生成器将工作 69 年,有一个接近今天日期的自定义纪元时间可以延迟溢出时间。69 年后,我们将需要一个新的纪元时间或采用其他技术来迁移 ID。
序列号 序列号是 12 位,给我们 2 ^ 12 = 4096 种组合。这个字段是 0,除非在同一台服务器上一毫秒内产生一个以上的 ID。理论上,一台机器每毫秒最多可以支持 4096 个新 ID。
总结
在这一章中,我们讨论了设计唯一 ID 生成器的不同方法:多主机复制、UUID、Ticket server 和 Twitter snowflake 的唯一 ID 生成器。 我们最终选择了 snowflake, 因为它支持我们所有的用例,并且在分布式环境中是可扩展的。
如果在采访结束时有多余的时间,这里有一些额外的谈话要点。
- 时钟同步。在我们的设计中,我们假设 ID 代服务器有相同的时钟。当一个服务器在多个核心上运行时,这个假设可能并不真实。在多机器的情况下也存在同样的挑战。时钟同步的解决方案不在本书的讨论范围之内;然而,了解问题的存在是很重要的。网络时间协议是解决这个问题最流行的方案。有兴趣的读者可以参考参考资料[4]。
- 节段长度的调整。例如,较少的序列号但较多的时间戳位对低并发和长期应用是有效的。
- 高可用性。由于 ID 生成器是一个关键任务的系统,它必须是高度可用的。
祝贺你走到了这一步! 现在给自己拍拍胸脯吧。干得好!
参考资料
[1]universally unique identifier
[2]ticket servers: distributed unique primary keys on the cheap:
[3]announcing snowflake
[4]network time protocol