设计一致性哈希
为了实现横向扩展,在服务器之间有效而均匀地分配请求/数据是很重要的。一致性哈希是实现这一目标的常用技术。但首先,让我们深入了解一下这个问题。
重哈希问题
如果你有 n 个缓存服务器,平衡负载的一个常用方法是使用下面的哈希方法。
serverIndex = hash(key) % N,其中 N 是服务器池的大小。
让我们用一个例子来说明它是如何工作的。如表 5-1 所示,我们有 4 个服务器和 8 个字符串 key 及其哈希值。
| key | hash | hash %4 |
|---|---|---|
| key0 | 18358617 | 1 |
| key1 | 26143584 | 0 |
| key2 | 18131146 | 2 |
| key3 | 35863496 | 0 |
| key4 | 34085809 | 1 |
| key5 | 27581703 | 3 |
| key6 | 38164978 | 2 |
| key8 | 22530351 | 3 |
Table 5-1
为了获取存储 key 的服务器,我们执行模块化操作 f(key) % 4。例如,hash(key0) % 4 = 1 意味着客户端必须联系服务器 1 来获取缓存的数据。图 5-1 显示了基于表 5-1 的 key 的分布。

当服务器池的大小是固定的,而且数据分布均匀时,这种方法效果很好。然而,当新的服务器被添加,或现有的服务器被移除时,问题就出现了。例如,如果服务器 1 下线了,服务器池的大小就变成了 3。使用相同的哈希函数,我们可以得到相同的键的哈希值。但是应用模块化操作会给我们带来不同的服务器索引,因为服务器的数量减少了 1。 通过应用哈希%3,我们得到如表 5-2 所示的结果。
| key | hash | hash %3 |
|---|---|---|
| key0 | 18358617 | 0 |
| key1 | 26143584 | 0 |
| key2 | 18131146 | 1 |
| key3 | 35863496 | 2 |
| key4 | 34085809 | 1 |
| key5 | 27581703 | 0 |
| key6 | 38164978 | 1 |
| key7 | 22530351 | 0 |
Table 5-2
图 5-2 显示了基于表 5-2 的新的 key 分布。

如图 5-2 所示,大多数 key 都被重新分配,而不仅仅是最初存储在脱机服务器(服务器 1)中的 key。这意味着,当服务器 1 离线时,大多数缓存客户会连接到错误的服务器来获取数据。这就造成了高速缓存失效的风暴。一致性哈希是一种有效的技术来缓解这个问题。
一致性哈希
引自维基百科。“一致性哈希是一种特殊的哈希,当哈希表被重新放大并使用一致性哈希时,平均只有 k/n 个 key 需要被重新映射,其中 k 是 key 的数量,n 是槽的数量。相比之下,在大多数传统的哈希表中,阵列槽数的变化导致几乎所有的键都被重新映射[1]"。
哈希空间和哈希环
现在我们了解了一致性哈希的定义,让我们来看看它是如何工作的。假设用 SHA-1 作为哈希函数 f,哈希函数的输出范围是:x0, x1, x2, x3, …, xn。在密码学中,SHA-1 的哈希空间从 0 到 2^160 - 1。这意味着 x0 对应于 0,xn 对应于 2^160 - 1,中间的其他哈希值都在 0 和 2^160 - 1 之间。 图 5-3 显示了哈希空间。

通过连接两端,我们得到一个哈希环,如图 5-4 所示。
哈希服务器
使用相同的哈希函数 f,我们根据服务器 IP 或名称将服务器映射到环上。图 5-5 显示,4 个服务器被映射到了哈希环上。

哈希键值
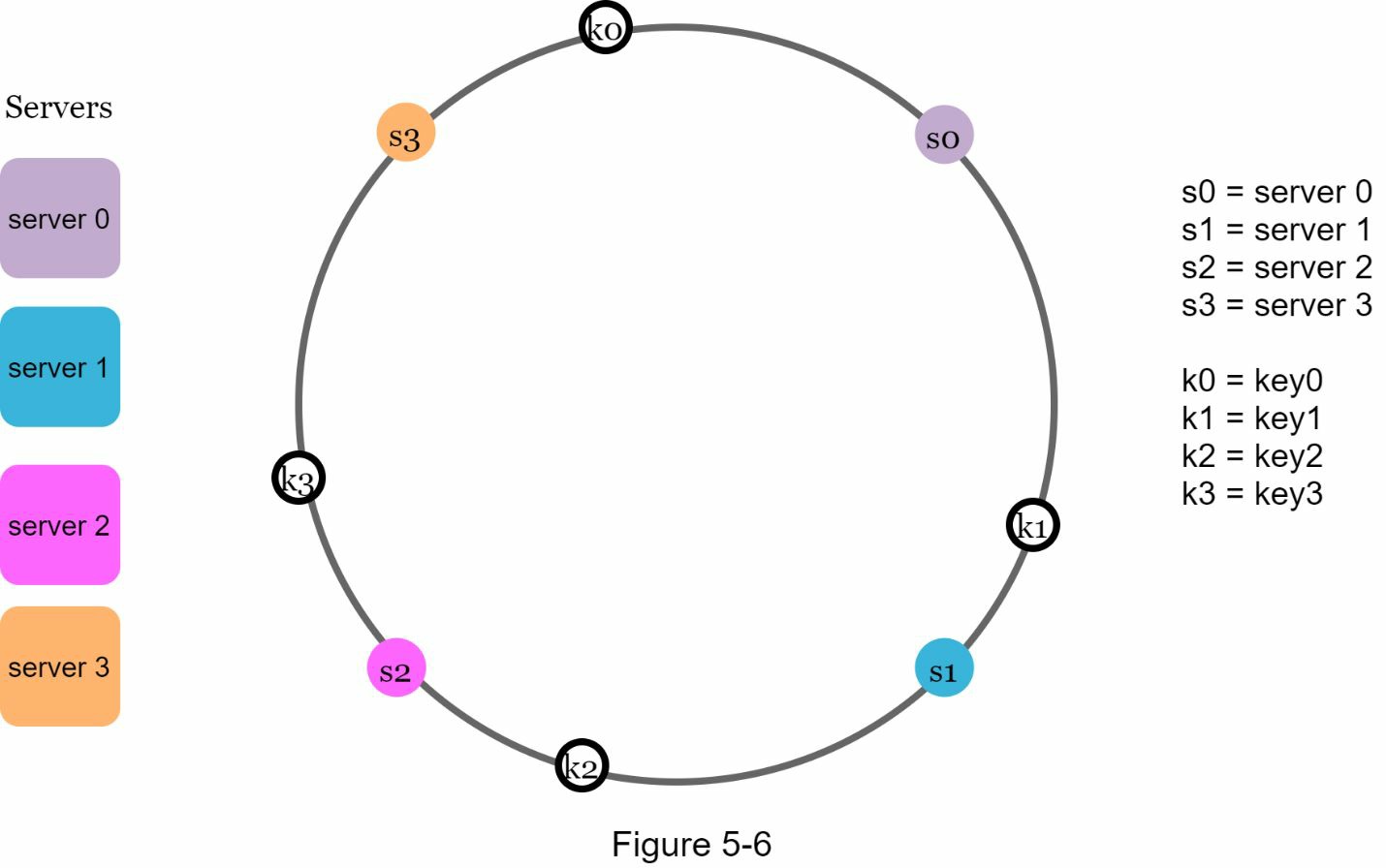
值得一提的是,这里使用的哈希函数与 “重哈希 “中的哈希函数不同,而且没有模块化操作。如图 5-6 所示,4 个缓存 key(key0、key1、key2 和 key3)被哈希在哈希环上
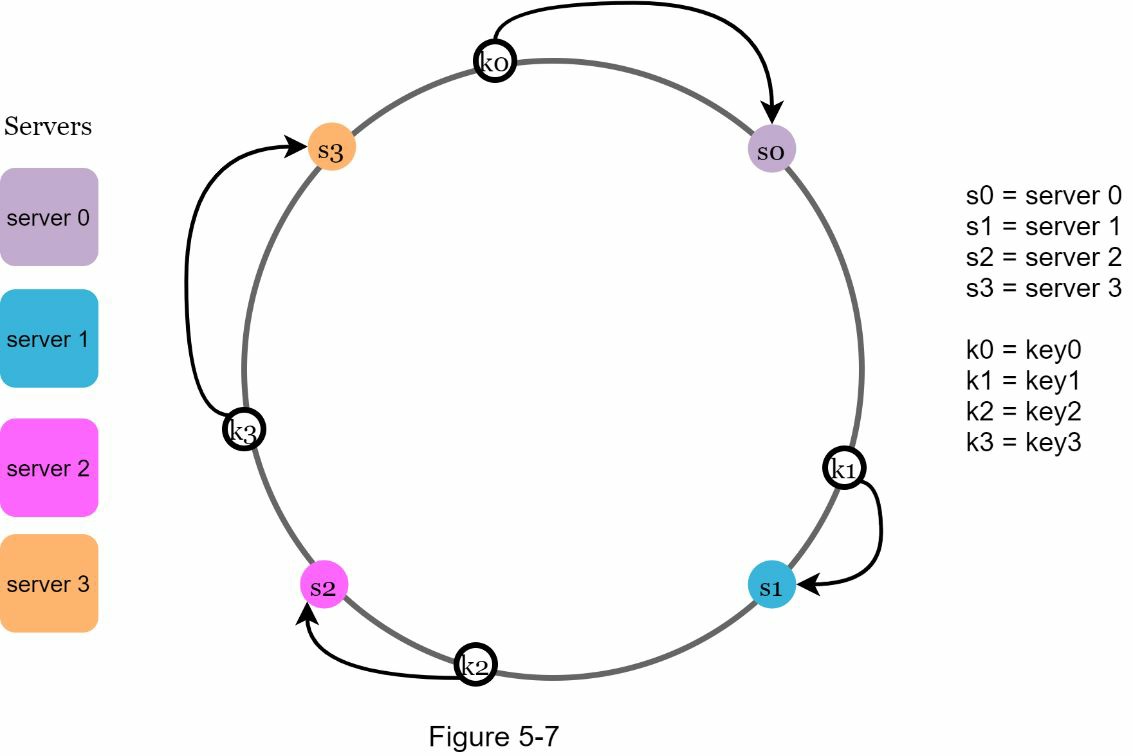
为了确定一把 key 存放在哪个服务器上,我们从 key 在环上的位置顺时针走,直到找到一个服务器。图 5-7 解释了这个过程。顺时针方向走,key 0 存储在服务器 0;key 1 存储在服务器 1;key 2 存储在服务器 2,key 3 存储在服务器 3。
添加一个服务器
使用上面描述的逻辑,增加一个新的服务器只需要重新分配一部分的 key。
在图 5-8 中,在增加一个新的服务器 4 后,只有 key0 需要重新分配,k1、k2 和 k3 仍然在相同的服务器上。让我们仔细看一下这个逻辑。现在,key 0 将被存储在服务器 4 上,因为服务器 4 是它从 key 0 在环上的位置顺时针方向移动所遇到的第一个服务器。其他的 key 不会根据一致的哈希算法进行重新分配。

基本方法中的两个问题
一致哈希算法是由麻省理工学院的 Karger 等人提出的[1]。其基本步骤是。
使用一个均匀分布的哈希函数将服务器和 key 映射到环上。
要想知道一个 key 被映射到哪个服务器,从 key 的位置开始顺时针走,直到找到环上的第一个服务器。
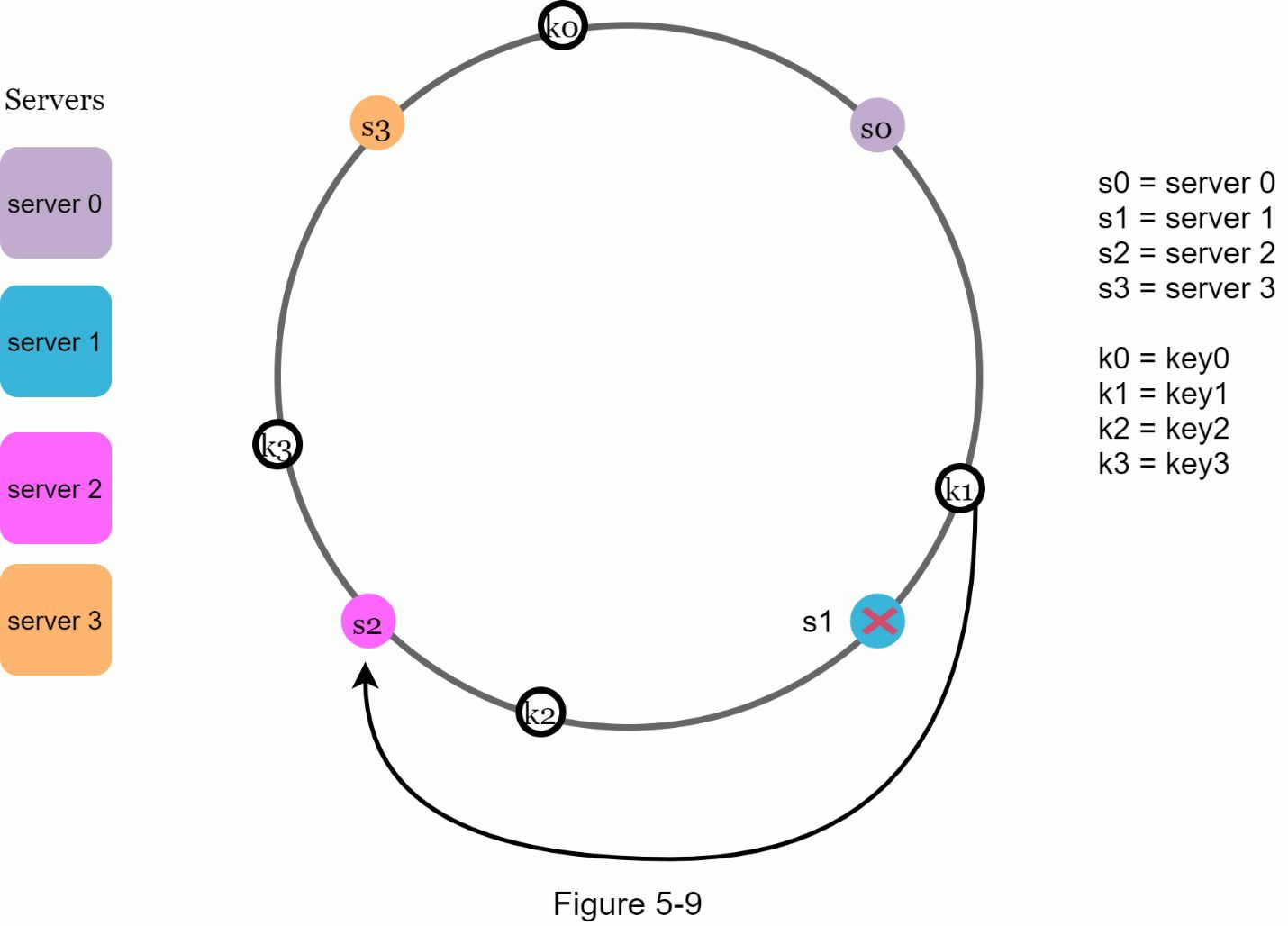
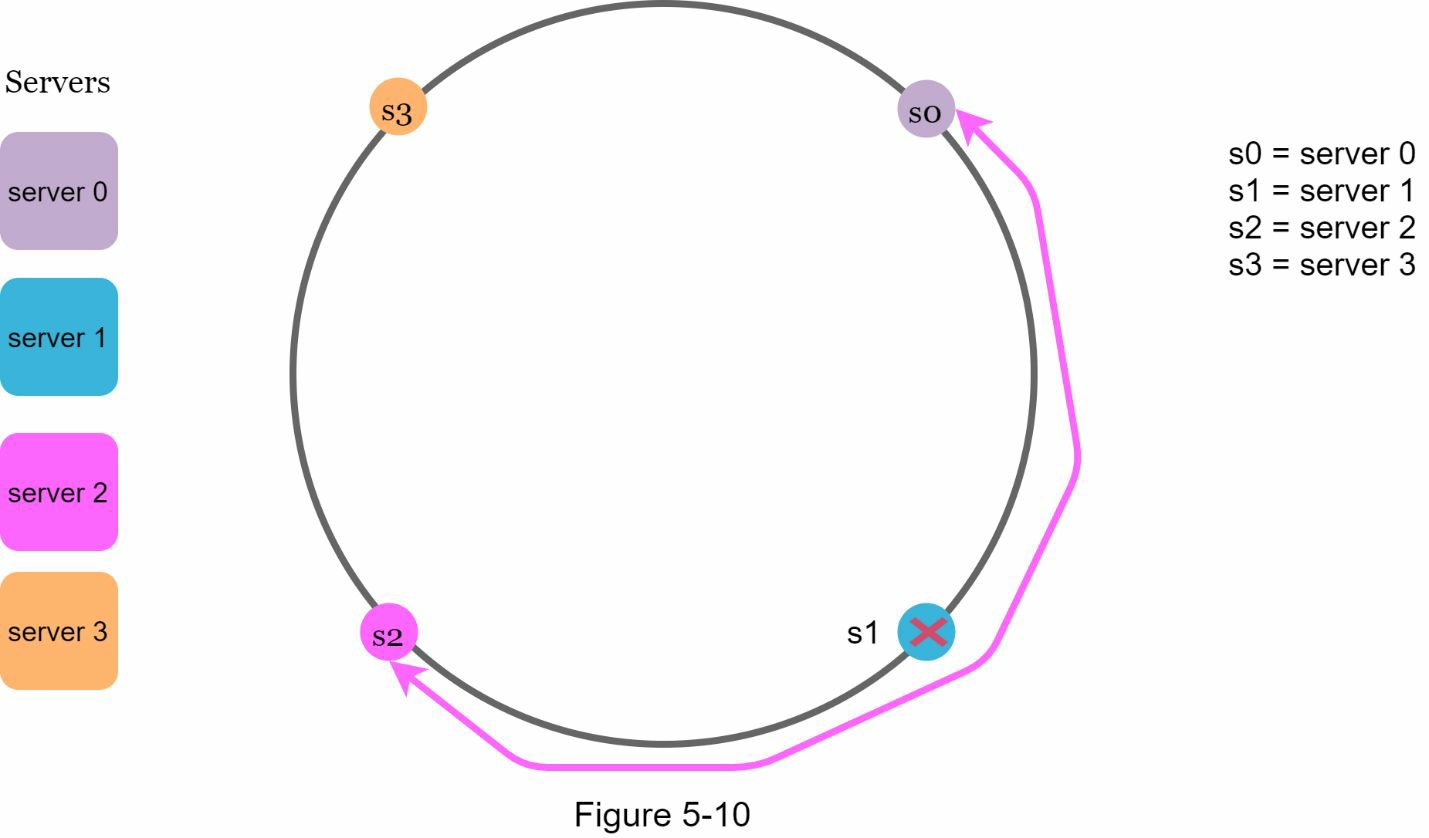
这种方法有两个问题。首先,考虑到服务器可以被添加或删除,不可能在环上为所有服务器保持相同大小的分区。分区是相邻服务器之间的哈希空间。分配给每个服务器的环上分区的大小有可能非常小,也有可能相当大。在图 5-10 中,如果 s1 被移除,s2 的分区(用双向箭头突出显示)是 s0 和 s3 的分区的两倍大。
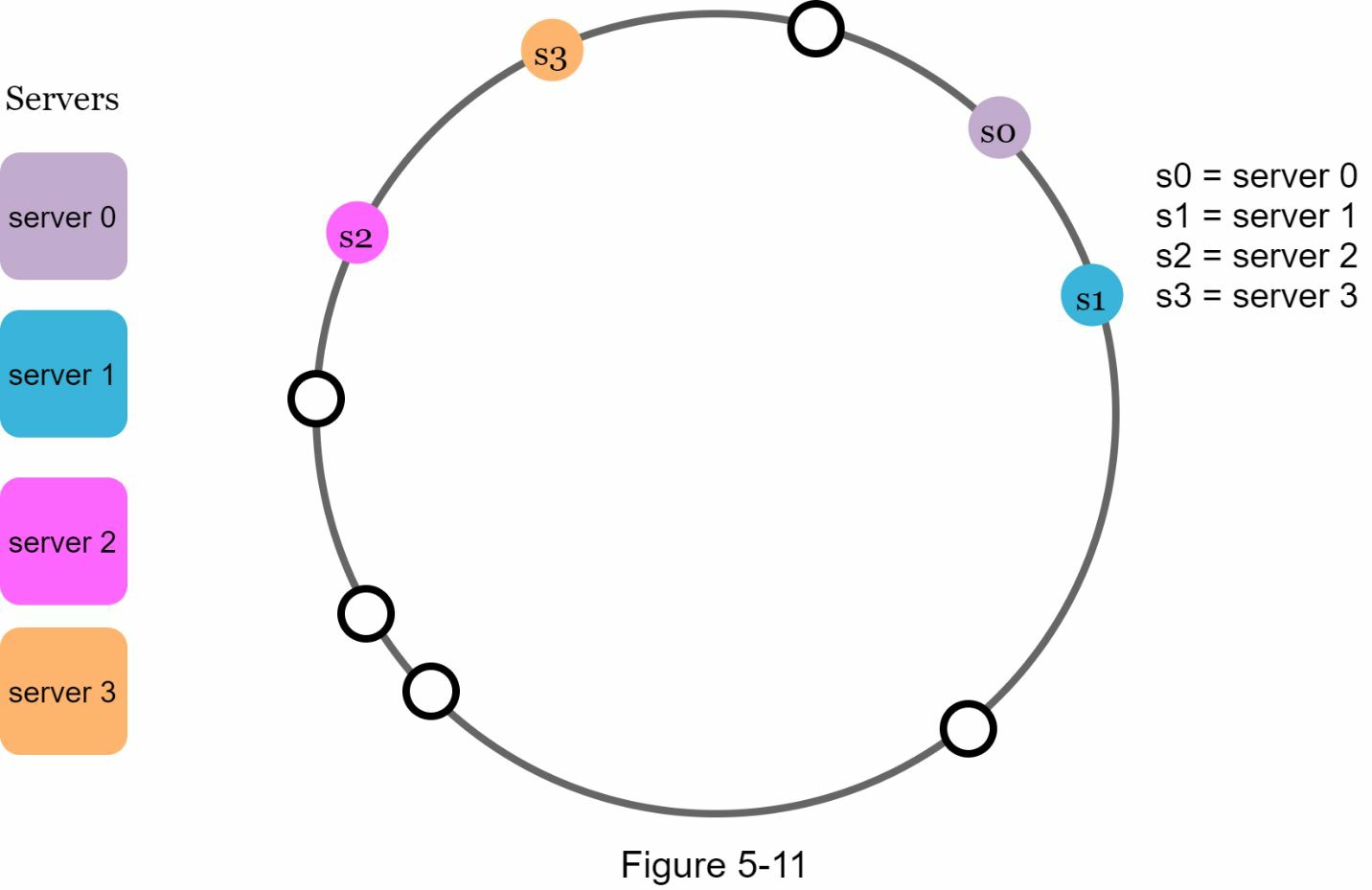
其次,在环上有可能出现非均匀的 key 分布。例如,如果服务器被映射到图 5-11 中所列的位置,大部分的 key 都存储在服务器 2 上。然而,服务器 1 和服务器 3 没有数据。
一种叫做虚拟节点或复制的技术被用来解决这些问题。
虚拟节点
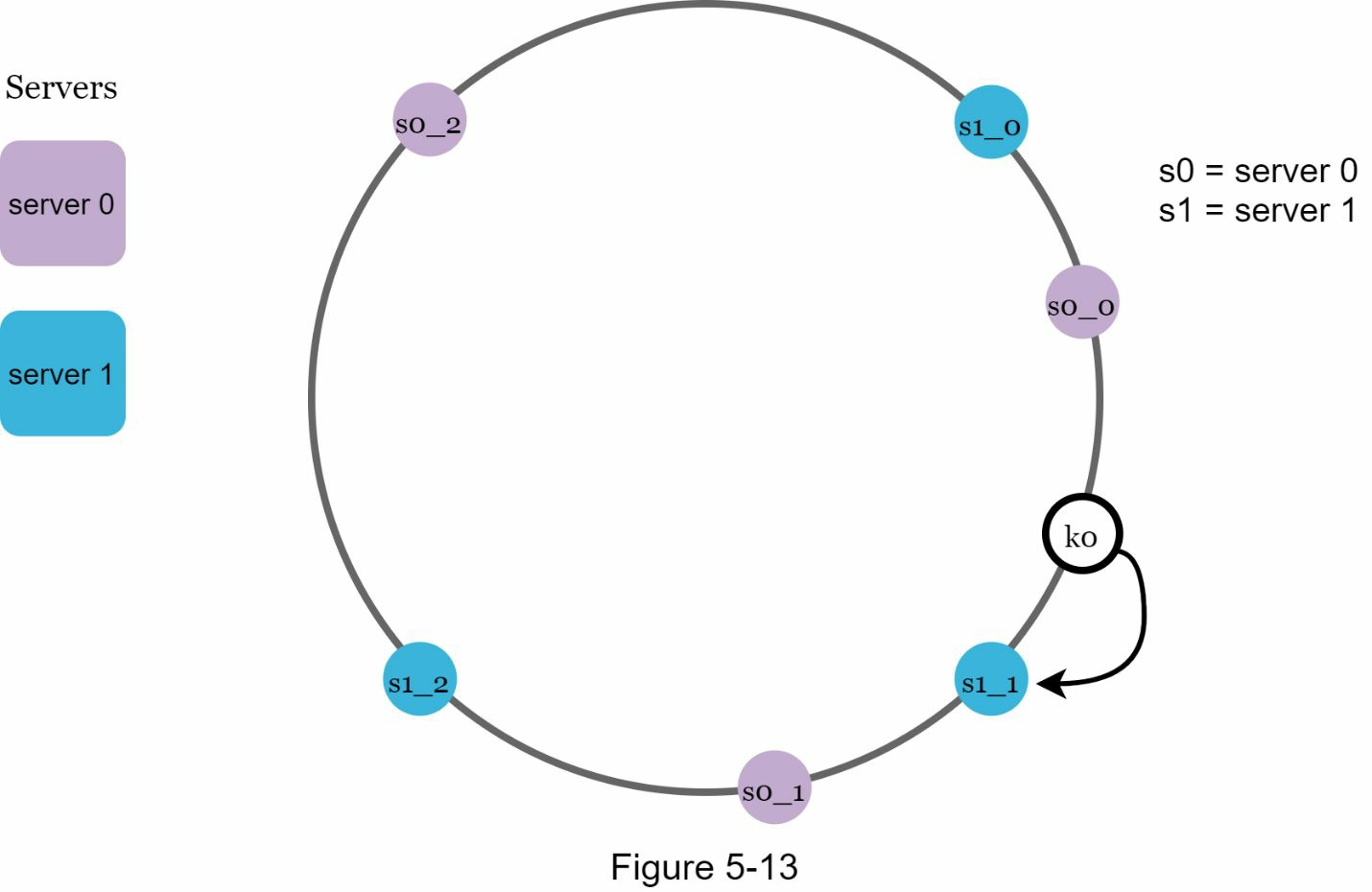
一个虚拟节点指的是真实的节点,每个服务器都由环上的多个虚拟节点代表。在图 5-12 中,服务器 0 和服务器 1 都有 3 个虚拟节点。3 是任意选择的;而在现实世界的系统中,虚拟节点的数量要大得多。我们不使用 s0,而是用 s0_0、s0_1 和 s0_2 来代表环上的服务器 0。同样地,s1_0、s1_1 和 s1_2 代表环上的服务器 1。通过虚拟节点,每个服务器负责多个分区。标签为 s0 的分区(边)由服务器 0 管理。 另一方面,标签为 s1 的分区则由服务器 1 管理。

随着虚拟节点数量的增加,key 的分布变得更加平衡。这是因为标准差随着虚拟节点的增加而变小,导致数据分布平衡。标准差衡量的是数据的分布情况。在线研究[2] 进行的实验结果表明,在一两百个虚拟节点的情况下,标准偏差在平均值的 5%(200 个虚拟节点)和 10%(100 个虚拟节点)之间。当我们增加虚拟节点的数量时,标准偏差会更小。然而,需要更多的空间来存储关于虚拟节点的数据。这是一种权衡,我们可以调整虚拟节点的数量以适应我们的系统要求。
寻找受影响的 key
当一个服务器被添加或删除时,有一部分数据需要重新分配。我们怎样才能找到受影响的范围来重新分配 key 呢?
在图 5-14 中,服务器 4 被添加到环上。受影响的范围从 s4(新添加的节点)开始,围绕着环逆时针移动,直到找到一个服务器(s3)。因此,位于 s3 和 s4 之间的 key 需要重新分配到 s4。

如图 5-15 所示,当一个服务器(s1)被移除时,受影响的范围从 s1(被移除的节点)开始,围绕环形网络逆时针移动,直到找到一个服务器(s0)。因此,位于 s0 和 s1 之间的 key 必须被重新分配到 s2。

总结
在本章中,我们深入讨论了一致性哈希的问题,包括为什么需要它以及它是如何工作的。一致性哈希的好处包括。
- 当服务器被添加或删除时,最小化的 key 被重新分配。
- 易于横向扩展,因为数据的分布更加均匀。
- 缓解热点 key 问题。对一个特定分片的过度访问可能导致服务器过载。想象一下,Katy Perry、Justin Bieber 和 Lady Gaga 的数据都在同一个分片上结束。一致性哈希有助于通过更均匀地分配数据来缓解这一问题。
一致性哈希在现实世界的系统中被广泛使用,包括一些引人注目的系统。
- 亚马逊的 Dynamo 数据库的分区组件[3]
- Apache Cassandra 中跨集群的数据分区[4]
- Discord 聊天应用程序[5]
- Akamai 内容分发网络 [6]
- 磁悬浮网络负载平衡器 [7]
恭喜你走到这一步! 现在给自己拍拍胸脯吧。干得好!
参考资料
[1]consistent hashing
[2]consistent hashing
[3]dynamo: amazon’s highly available key-value store
[4]cassandra - a decentralized structured storage system
[5]how discord scaled elixir to 5,000,000 concurrent users
[6]cs168:the modern algorithmic toolbox lecture #1: introduction and consistent hashing
[7]maglev: a fast and reliable software network load balancer